单例的目的是保证一个类只有一个实例,这样代码在调用的时候不需要频繁的初始化,但是在调试的过程中,单例可能出现因为多线程访问导致的概率性bug,本文主要讨论单例出现的这种问题
单例代码
为了支持单例,最明显的代码就是实现一个getInstance函数,这个函数中在第一次访问的时候new自己的对象,之后所有的调用通过getInstance来调用类的函数,代码示例如下:
GlobalConfig *GlobalConfig::getInstance() { if(instance == nullptr) // a instance = new GlobalConfig; // b return instance; }
多线程环境
对于单例,如果在单线程环境下,上述代码不会有任何问题,如果instance是nullptr,则新建一个,如果不是,则返回这个instance。
但是如果是多线程的情况,满足instance都没有创建的情况下,两个线程同时调用了getInstance函数,那么可能出现:
- 第一个线程正在执行b位置代码
- 而第二个线程正在执行a代码
第二个线程判断了instance此时还是nullptr,所以再一次构造了GlobalConfig,这样子我们对这个单例构造了两次。这是不必要的开销。
为了解决多线程环境下出现的单例构造两次的问题,我们可以对这段代码加锁,如下
GlobalConfig *GlobalConfig::getInstance() { LOCK(); if(instance == nullptr) // a instance = new GlobalConfig; // b UNLOCK(); return instance; }
此时我们通过锁解决了上面提到的单例构造两次的问题,因为当第一个线程正在执行时会上锁,这样第二个线程就不会重入代码内部。因为锁也是原子的,所以我们似乎解决了单例构造两次的问题。
但是,上面代码会引入新的问题,我们知道getInstance函数在99%的情况下instance是有值的,而在1%的情况下是需要构造的,这也就导致了这个锁在99%的情况下是不需要的。那么怎么优化这个问题呢?
double-check
对于上面的代码,我们需要解决锁带来的性能开销问题,因为我们不能因为1%的场景去让代码执行99%的任务。所以我们需要进行double-check,那么具体是什么样的呢,如下代码
GlobalConfig *GlobalConfig::getInstance() { if(instance == nullptr) { LOCK(); if(instance == nullptr) // a instance = new GlobalConfig; // b UNLOCK(); } return instance; }
这段代码通过重复检测instance的值,从而避免了99%的不必要加锁操作。它看似会正常工作了。
但是我们对构造GlobalConfig这个类需要再分析一下,它主要做如下事情
- 分配内存
- 调用构造函数
- 将内存地址返回给instance
如果上面步骤1,2,3都是顺序执行的,那么这一切都是正常的,那么假设步骤2和步骤3的顺序颠倒呢?
那么程序是否崩溃就取决于是否访问到没有权限不可访问的区域了,如果访问到了,就崩溃,如果不是,那么可能修改错误的值,或者存在了一个隐藏的bug。
CPU乱序执行
根据上面提到的,步骤2和步骤3在体系架构中真会出现,这主要原因是cpu的乱序执行。
我们知道一条指令在cpu的流水线执行包含如下几个部分
取指---译码---执行---访存---写回
这些步骤是顺序的,但是一般来说CPU会有多级流水线,这样就会出现如下情况。以三级流水线为例
取指---译码---执行---访存---写回 取指---译码---执行---访存---NOP 取指---译码---执行---NOP---写回
而且,我们知道CPU访问内存的速度是慢于CPU自身时钟频率的,所以在取指和访存以及写回三个步骤上会比较慢。所以为了加快CPU的指令执行,CPU乱序执行的就出现了。其含义是:
- 在指令执行过程中,如果后面的指令不依赖前面的指令,那么就可以将后面的指令提前到前面执行
对于上面的例子,我们知道步骤2是调用构造函数,步骤3是将内存地址返回,对于它们而言,其执行是理论可以乱序的,所以就可以出现运行步骤是 1-->3-->2 这样的现象。
根据上面提到的CPU乱序问题,我们也可以很好解决,那就是让两行代码出现数据依赖就行了,那么代码如下
GlobalConfig *GlobalConfig::getInstance() { if(instance == nullptr) { LOCK(); if(instance == nullptr) // a GlobalConfig* temp = new GlobalConfig; // b instance = temp //c UNLOCK(); } return instance; }
从代码的第b行和第c行看,我们将构造的对象赋值给了temp,然后再将temp传递给instance。它能够完美规避CPU乱序的问题。
那还有什么问题没有呢? 实则不然,我们知道编译器会将指令乱序,这段代码仍可能出现乱序执行的问题。
编译器乱序
虽然我们在代码b和代码c行特地构造了数据依赖,让我们人眼直观来看CPU不会针对这行指令进行乱序了,但是我们知道通常情况下代码编译成汇编的时候,编译器会优化代码,如果关闭优化如O(0),则代码执行效率低,所以通常编译默认的优化等级是O(2)。在默认情况下,上述代码编译器会认为temp是没有意义的变量,故合并两行代码。
这样,我们看似自行做的优化,实际上在编译阶段就已经被编译器进行了负优化了。那么我们只能寻找其他办法。
barrier指令
barrier的含义就是栅栏的意思,它同样适用于编译器,在aarch64中,有三种barrier指令,如下
- DMB:Data Memory Barrier,针对内存访问,所有数据在DMB之前访问完成,所有数据在DMB之后,不能乱序到DMB之前。
- DSB:Data Synchronization Barrier,比DMB更严格,对于CPU流水线上的访存,它禁止了DSB之后的访存完全不会开始,也确保了DSB之前的访存会完全结束(访存/回写)
- ISB:Instruction Synchronization Barrier,从指令角度,在DSB之前的指令必须流水线完全完成,然后清空所有的指令缓存,重新取指执行。
对于上述的问题,我们知道编译器也会执行乱序,所以为了让编译器不做乱序优化,我们在其数据依赖的中间添加任意的barrier指令,避免编译器的错误优化,代码如下
GlobalConfig *GlobalConfig::getInstance() { if(instance == nullptr) { LOCK(); if(instance == nullptr) // a GlobalConfig* temp = new GlobalConfig; // b barrier(); //d instance = temp //c UNLOCK(); } return instance; }
如上,我们添加了第d行,这个barrier可以是任意的barrier指令,例如DMB,它可以使得编译器不进行乱序优化。这样就真正的解决了单例在多线程中的所有问题。
最优解
根据上面的介绍,我们为了解决单例在多线程访问中并发的问题做了很多的思考,使得代码看起来非常的乱,甚至是过度优化,对于这种情况,实际上还有最优解。那就是资源最早初始化。
这里表达的意思就是:
如果把getInstance函数放在初始化的单线程中,这样所有的多线程访问都不可能进入instance == nullptr 的逻辑内。
如果就将约束程序员在代码的第一次进入getInstance时是单线程的,那或许比较困难(谁知道其他程序员怎么想~),那么另一种方法或许风险更小,就是在每个线程开始的时候,主动调用如下
GlobalConfig* const instance = GlobalConfig::getInstance();
这样这个instance的值引用的instance并且保存在cache中。从而使得后面调用所有的getInstance都不需要考虑多线程重入的问题。
总结
本文基于线程安全的角度介绍了单例在多线程中的bug,如果我们为了解决一个一个多线程重入导致的问题,那么代码可读性就会很差,并且容易出现负优化,如果我们在这种情况下,对每个线程的最开始主动增加一次getInstance调用,后面的调用实际上利用了cache,那么反而其整体性能最高。
参考文章
https://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf
在处理内存泄漏问题上,我们有个bug就是循环播放14天视频,会出现内存上升大概20M的样子,也就是这个问题,发现了QThread的隐藏问题:如果QThread完成之后,不显式的连接finished信号并执行deleteLater,那么QThread就会造成内存泄漏。这个内存泄漏用任意的内存泄漏检测工具都可以轻易的检测出来。关于本问题,连续播放视频一周,那么意味着创建了无数个QThread结构实例,但是没有被回收。
泄漏堆栈
本文基于asan获取的堆栈如下
Indirect leak of 272000 byte(s) in 1700 object(s) allocated from: #0 0x7f83cc0d5c in operator new(unsigned long) (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0xeed5c) #1 0x7f7fb9e89c in QThread::QThread(QObject*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa189c) #2 0x7f7fb9ea60 in QThread::createThreadImpl(std::future<void>&&) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa1a60) #3 0x5564d9e098 in create<MpvCore::LoadFileInfo()::<lambda()> > /usr/include/aarch64-linux-gnu/qt5/QtCore/qthread.h:235 #4 0x5564d9e098 in MpvCore::LoadFileInfo() core/mpvcore.cpp:1163 #5 0x5564da679c in MpvCore::event(QEvent*) core/mpvcore.cpp:1670 #6 0x7f809088e8 in QApplicationPrivate::notify_helper(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Widgets.so.5+0x15e8e8) #7 0x7f80911eec in QApplication::notify(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Widgets.so.5+0x167eec) #8 0x7f7fd6a9c0 in QCoreApplication::notifyInternal2(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x26d9c0) #9 0x7f7fd6d8d4 in QCoreApplicationPrivate::sendPostedEvents(QObject*, int, QThreadData*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2708d4) #10 0x7f7fdc89c4 (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2cb9c4) #11 0x7f80f44708 in g_main_context_dispatch (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51708) #12 0x7f80f44974 (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51974) #13 0x7f80f44a18 in g_main_context_iteration (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51a18) #14 0x7f7fdc7e70 in QEventDispatcherGlib::processEvents(QFlags<QEventLoop::ProcessEventsFlag>) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2cae70) #15 0x7f7fd6916c in QEventLoop::exec(QFlags<QEventLoop::ProcessEventsFlag>) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x26c16c) #16 0x7f7fd71770 in QCoreApplication::exec() (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x274770) #17 0x5564d7ed60 in main src/main.cpp:68 #18 0x7f7f690d8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #19 0x5564d886a4 (/home/kylin/kylin-video+0x686a4)
根据上面的堆栈,我们看到泄漏存在于QThread的构造函数中。我们翻一下qtbase的源码
QThread源码
class QThreadCreateThread : public QThread { public: explicit QThreadCreateThread(std::future<void> &&future) : m_future(std::move(future)) { } private: void run() override { m_future.get(); } std::future<void> m_future; }; QThread *QThread::createThreadImpl(std::future<void> &&future) { return new QThreadCreateThread(std::move(future)); } QThread::QThread(QObject *parent) : QObject(*(new QThreadPrivate), parent) { Q_D(QThread); // fprintf(stderr, "QThreadData %p created for thread %p\n", d->data, this); d->data->thread = this; }
可以很明显的看到QThread执行了new操作,和asan给出的报告相符合。
关于QObject
我们参照qt的文档如下
When any QObject in the tree is deleted, if the object has a parent, the destructor automatically removes the object from its parent
如果QObject对象有父对象,那么会在父对象中析构所有的成员
但是我们要知道的是QThread继承于QObject,但是没有父对象
关于QThread
qt的文档隐晦的提示你要调用QObject::deleteLater()。文章链接如下
void QThread::finished() This signal is emitted from the associated thread right before it finishes executing. When this signal is emitted, the event loop has already stopped running. No more events will be processed in the thread, except for deferred deletion events. This signal can be connected to QObject::deleteLater(), to free objects in that thread.
总结
根据上面的信息,我们可以总结出来,QThread创建的线程,如果没有父对象,那么需要显式的连接finished信号来执行deleteLater,否则就需要将其绑定到一个对象上。所以解决问题的方法有两种:
- 绑定父对象
QThread* thread = new QThread; Worker* worker = new Worker; worker->setParent(thread); worker->moveToThread(thread);
这种情况下,其对象是否析构取决于worker的管理。
- 连接finished
QThread::connect(thread, &QThread::finished, thread, &QThread::deleteLater);
一般QThread不会频繁的绑定对象父子关系,这样不容易管理,所以对于父子关系不清晰的代码,建议直接连接finished即可
测试
对于bug而言,我解决此问题的方法是连接finished,为了测试,下面提供了复现这个问题的测试代码
#include <QThread> #include <QDebug> int main(int argc, char *argv[]) { Q_UNUSED(argc); Q_UNUSED(argv); for (int i = 0; i < 100; ++i) { QThread* thread = QThread::create([i]{ qDebug() << "Thread Started:" << i; }); thread->start(); // QThread::connect(thread, &QThread::finished, thread, &QThread::deleteLater); } QThread::sleep(3); return 0; }
我创建100个线程,如果不连接finished信号调用deleteLater,那么可以很明显的报告内存泄漏,如果添加信号则代码正常。
================================================================= ==52273==ERROR: LeakSanitizer: detected memory leaks Indirect leak of 16000 byte(s) in 100 object(s) allocated from: #0 0x7fbcb04d5c in operator new(unsigned long) (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0xeed5c) #1 0x7fbbfce89c in QThread::QThread(QObject*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa189c) #2 0x7fbbfcea60 in QThread::createThreadImpl(std::future<void>&&) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa1a60) #3 0x55855c38b4 in create<main(int, char**)::<lambda()> > /usr/include/aarch64-linux-gnu/qt5/QtCore/qthread.h:199 #4 0x55855c38b4 in main /tmp/qthread/test.cpp:9 #5 0x7fbbac2d8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #6 0x55855c41e0 (/root/test+0x41e0) Indirect leak of 12000 byte(s) in 100 object(s) allocated from: #0 0x7fbcb04d5c in operator new(unsigned long) (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0xeed5c) #1 0x7fbbfce8fc in QThread::QThread(QObject*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa18fc) #2 0x7fbbfcea60 in QThread::createThreadImpl(std::future<void>&&) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa1a60) #3 0x55855c38b4 in create<main(int, char**)::<lambda()> > /usr/include/aarch64-linux-gnu/qt5/QtCore/qthread.h:199 #4 0x55855c38b4 in main /tmp/qthread/test.cpp:9 #5 0x7fbbac2d8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #6 0x55855c41e0 (/root/test+0x41e0) Indirect leak of 10400 byte(s) in 100 object(s) allocated from: #0 0x7fbcb04d5c in operator new(unsigned long) (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0xeed5c) #1 0x7fbbfd6e40 in QWaitCondition::QWaitCondition() (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa9e40) #2 0x7fbbfce8f0 in QThread::QThread(QObject*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa18f0) #3 0x7fbbfcea60 in QThread::createThreadImpl(std::future<void>&&) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa1a60) #4 0x55855c38b4 in create<main(int, char**)::<lambda()> > /usr/include/aarch64-linux-gnu/qt5/QtCore/qthread.h:199 #5 0x55855c38b4 in main /tmp/qthread/test.cpp:9 #6 0x7fbbac2d8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #7 0x55855c41e0 (/root/test+0x41e0) Indirect leak of 3200 byte(s) in 100 object(s) allocated from: #0 0x7fbcb04d5c in operator new(unsigned long) (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0xeed5c) #1 0x7fbbfcea54 in QThread::createThreadImpl(std::future<void>&&) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0xa1a54) #2 0x55855c38b4 in create<main(int, char**)::<lambda()> > /usr/include/aarch64-linux-gnu/qt5/QtCore/qthread.h:199 #3 0x55855c38b4 in main /tmp/qthread/test.cpp:9 #4 0x7fbbac2d8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #5 0x55855c41e0 (/root/test+0x41e0) SUMMARY: AddressSanitizer: 41600 byte(s) leaked in 400 allocation(s).
最近在调试程序内存的问题时,通过asan挂上内存监听,遇到了一个stack-use-after-scope的错误,asan调试其他问题的介绍后面有空再介绍,本文通过asan发现了C++一个关于生命周期的bug,它会导致程序错误的使用栈。问题比较经典,故特定分享一下。
问题现象
在使用 播放器播放视频的时候,如果不断的移动播放器进度条,有非常小的概率导致移动失败。
再加上调试过程中,移动进度条播放时,相关代码存在内存泄漏,故相应代码部位添加了asan用于检测。
调试和日志
开启asan的方式简单介绍如下
QMAKE_CXXFLAGS += -fsanitize=address -g QMAKE_LFLAGS += -fsanitize=address
然后挂上asan的库运行即可
LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0 ./kylin-video
其他问题我们先不关注,这里只关注本文章讨论的stack-use-after-scope,故asan检测到的错如下
==88163==ERROR: AddressSanitizer: stack-use-after-scope on address 0x007ffe54b9b0 at pc 0x007f99a74504 bp 0x007ffe54ab40 sp 0x007ffe54abb8 READ of size 3 at 0x007ffe54b9b0 thread T0 #0 0x7f99a74500 (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0x64500) #1 0x7f9753d408 in bstr0 ../misc/bstr.h:61 #2 0x7f9753d408 in set_node_arg ../input/cmd.c:179 #3 0x7f9753dfd8 in cmd_node_array ../input/cmd.c:227 #4 0x7f9753dfd8 in mp_input_parse_cmd_node ../input/cmd.c:301 #5 0x7f9753e638 in mp_input_parse_cmd_strv ../input/cmd.c:502 #6 0x7f9755f2ec in mpv_command_async ../player/client.c:1196 #7 0x557793118c in MpvCore::Seek(int, bool, bool) core/mpvcore.cpp:588 #8 0x5577932a74 in operator() core/mpvcore.cpp:1330 #9 0x5577932a74 in call /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:146 #10 0x5577932a74 in call<QtPrivate::List<int>, void> /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:256 #11 0x5577932a74 in impl /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:439 #12 0x5577932a74 in impl /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:432 #13 0x7f95bd79e4 in QMetaObject::activate(QObject*, int, int, void**) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x29c9e4) #14 0x5577b02500 in GlobalUserSignal::sigSeek(int) .moc/moc_globalsignal.cpp:1047 #15 0x55779e1174 in GlobalUserSignal::seek(int) global/globalsignal.h:47 #16 0x55779e1174 in operator() widget/contralbar.cpp:647 #17 0x55779e1174 in call /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:146 #18 0x55779e1174 in call<QtPrivate::List<>, void> /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:256 #19 0x55779e1174 in impl /usr/include/aarch64-linux-gnu/qt5/QtCore/qobjectdefs_impl.h:439 #20 0x7f95be52b8 (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2aa2b8) #21 0x7f95bd8264 in QObject::event(QEvent*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x29d264) #22 0x7f967468e8 in QApplicationPrivate::notify_helper(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Widgets.so.5+0x15e8e8) #23 0x7f9674feec in QApplication::notify(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Widgets.so.5+0x167eec) #24 0x7f95ba89c0 in QCoreApplication::notifyInternal2(QObject*, QEvent*) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x26d9c0) #25 0x7f95c051ac in QTimerInfoList::activateTimers() (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2ca1ac) #26 0x7f95c05adc (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2caadc) #27 0x7f96d82708 in g_main_context_dispatch (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51708) #28 0x7f96d82974 (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51974) #29 0x7f96d82a18 in g_main_context_iteration (/lib/aarch64-linux-gnu/libglib-2.0.so.0+0x51a18) #30 0x7f95c05e70 in QEventDispatcherGlib::processEvents(QFlags<QEventLoop::ProcessEventsFlag>) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x2cae70) #31 0x7f95ba716c in QEventLoop::exec(QFlags<QEventLoop::ProcessEventsFlag>) (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x26c16c) #32 0x7f95baf770 in QCoreApplication::exec() (/lib/aarch64-linux-gnu/libQt5Core.so.5+0x274770) #33 0x55778f3dc0 in main src/main.cpp:68 #34 0x7f954ced8c in __libc_start_main (/lib/aarch64-linux-gnu/libc.so.6+0x20d8c) #35 0x55778ff55c (/home/kylin/kylin-video+0xdf55c) Address 0x007ffe54b9b0 is located in stack of thread T0 at offset 928 in frame #0 0x557793040c in MpvCore::Seek(int, bool, bool) core/mpvcore.cpp:552 This frame has 28 object(s): [48, 49) '<unknown>' [64, 65) '<unknown>' [80, 81) '<unknown>' [96, 97) '<unknown>' [112, 113) '<unknown>' [128, 129) '<unknown>' [144, 145) '<unknown>' [160, 161) '<unknown>' [176, 184) '<unknown>' [208, 216) '<unknown>' [240, 248) '<unknown>' [272, 280) 'tmp' (line 565) [304, 312) '<unknown>' [336, 344) '<unknown>' [368, 376) '<unknown>' [400, 408) '<unknown>' [432, 440) '<unknown>' [464, 472) '<unknown>' [496, 504) '__dnew' [528, 536) '<unknown>' [560, 568) '__dnew' [592, 624) '<unknown>' [656, 680) 'args' (line 573) [720, 752) 'args' (line 568) [784, 816) '<unknown>' [848, 880) 'args' (line 587) [912, 944) '<unknown>' <== Memory access at offset 928 is inside this variable [976, 1016) 'args' (line 581) HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork (longjmp and C++ exceptions *are* supported) SUMMARY: AddressSanitizer: stack-use-after-scope (/usr/lib/aarch64-linux-gnu/libasan.so.5.0.0+0x64500) Shadow bytes around the buggy address: 0x001fffca96e0: f8 f2 00 00 00 f2 00 00 00 f2 00 00 00 f2 00 00 0x001fffca96f0: 00 f2 00 00 00 f2 00 00 f8 f2 00 00 00 f2 00 00 0x001fffca9700: 00 f2 00 00 f8 f2 00 00 f8 f2 f2 f2 f8 f8 f8 f8 0x001fffca9710: f2 f2 f2 f2 00 00 00 f2 f2 f2 f2 f2 00 00 00 00 0x001fffca9720: f2 f2 f2 f2 00 00 00 00 f2 f2 f2 f2 00 00 00 00 =>0x001fffca9730: f2 f2 f2 f2 f8 f8[f8]f8 f2 f2 f2 f2 00 00 00 00 0x001fffca9740: 00 f3 f3 f3 f3 f3 00 00 00 00 00 00 00 00 00 00 0x001fffca9750: 00 00 00 00 00 00 f1 f1 f1 f1 00 f3 f3 f3 00 00 0x001fffca9760: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x001fffca9770: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0x001fffca9780: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Shadow byte legend (one shadow byte represents 8 application bytes): Addressable: 00 Partially addressable: 01 02 03 04 05 06 07 Heap left redzone: fa Freed heap region: fd Stack left redzone: f1 Stack mid redzone: f2 Stack right redzone: f3 Stack after return: f5 Stack use after scope: f8 Global redzone: f9 Global init order: f6 Poisoned by user: f7 Container overflow: fc Array cookie: ac Intra object redzone: bb ASan internal: fe Left alloca redzone: ca Right alloca redzone: cb Shadow gap: cc ==88163==ABORTING
关于asan的一下解释后面更新,这里通过错误我们看到了stack-use-after-scope,这个什么意思呢?如下
- stack-use-after-scope 指的是在栈区变量生命周期之外使用到了栈区变量
通俗点就是,访问了一个作用域之外的栈变量。
此时,通过反汇编代码,可以看到真正存在问题的汇编如下
0x0000007ff74133f8 <+536>: ldr x23, [x23]
可以看到这是一个取值操作,根据汇编上下文和代码上下文分析,其代码如下
int r = m_option_parse(log, opt, bstr0(cmd->name), bstr0(val->u.string), dst);
对于取值,我们可以看到val->u.string,随机可以通过gdb打印相关值,如下
(gdb) p val->u.string $6 = 0x7fffffe5b8 "32"
可以看到,这里ldr就是把0x7fffffe5b8里面的值32取走了,符合bstr0(val->u.string)的逻辑。我们看看程序的栈区范围如下
kylin@kylin:~$ cat /proc/198018/maps | grep stack 7ffffdf000-8000000000 rw-p 00000000 00:00 0 [stack]
可以看到0x7fffffe5b8就是栈区的变量。
我们知道问题是播放器点击进度条的时候概率出现的,所以我们回到播放器的代码分析
void MpvCore::Seek(int pos, bool relative, bool osd) const char *args[] = {"seek", QString::number(pos).toStdString().c_str(), "absolute", NULL}; mpv_command_async(m_mpvHandle, MPV_REPLY_COMMAND, args); }
这里32的字符串的值就是QString::number(pos).toStdString().c_str()传递进去的。
我们还需要留意一个细节,那就是mpv_command_async,稍微跟踪一下代码如下
mpv_command_async run_async_cmd run_async mp_dispatch_enqueue
到这里我们可以清楚了,mpv的控制是异步接口,默认的命令通过队列管理,异步触发。
分析问题
根据上面的代码分析,调试和日志,我们知道了这是在一个异步请求上出现的访问了作用域之外的栈变量。
也就是说,args的构造中使用了栈变量,它标记销毁了,所以我们重点看args是如何构造的
const char *args[] = {"seek", QString::number(pos).toStdString().c_str(), "absolute", NULL};
我们可以知道,"seek" "absolute" 都是只读数据区,那么唯一出现在0x7fffffe5b8位置,也就是栈区的值就是QString::number(pos).toStdString().c_str()。 那么我们可以得出结论
- QString::number(pos).toStdString().c_str() 返回的值,在其作用域之外会被回收
- 代码是异步的,Seek函数调用完毕之后,栈区会回收局部变量
为了解决这个问题,我们就要从c++关于prvalue(pure rvalue:纯右值),也就是临时变量的生命周期谈起,相关文章如下,有兴趣的可以直接翻阅
理论支持
根据上面文献的描述,我们在如下情况下可以延长生命周期
- binding a reference to a prvalue
- initializing an object of type std::initializer_list< T > from a brace-enclosed initializer list (since C++11)
- returning a prvalue from a function
- conversion that creates a prvalue (including T(a, b, c) and T{})
- lambda expression (since C++11)
- copy-initialization that requires conversion of the initializer,
- reference-initialization to a different but convertible type or to a bitfield. (until C++17)
- when performing member access on a class prvalue
- when performing an array-to-pointer conversion or subscripting on an array prvalue
- for unevaluated operands in sizeof and typeid
- when a prvalue appears as a discarded-value expression
根据上面的描述,可以选用如下两种来解决此问题
- binding a reference to a prvalue
- copy-initialization that requires conversion of the initializer
其他的并不符合当前代码上下文状态。
给纯右值做引用绑定
std::string&& str = QString::number(pos).toStdString(); const char *args[] = {"seek", str.c_str(), "absolute", NULL};
这里 && 是使用右值引用,它等效于const情况下的左值引用,如下
const std::string& str = QString::number(pos).toStdString(); const char *args[] = {"seek", str.c_str(), "absolute", NULL};
这样可以实现对c_str()这个栈区的变量进行延长生命周期
拷贝初始化
std::string str = QString::number(pos).toStdString(); const char *args[] = {"seek", str.c_str(), "absolute", NULL};
这里直接初始化了一个str,对于args的传递,我们使用初始化完成的str来访问c_str(),这样的方式延长了其生命周期。
总结
至此,我们通过分析了c++关于临时变量延长生命周期的方式,解决了一个概率很低的bug(隐秘的bug),此bug一般不会出现问题,但长时间运行和压力测试就会出现错误,通过前期的分析和借助asan工具,可以很好的地位此问题。
另一方面,此问题是关于c++的string类型的生命周期问题,c_str()是当时栈区的临时变量,QString::number(pos).toStdString()如果和c_str()一起写,也就是QString::number(pos).toStdString().c_str(),那么这个string作为临时变量,它的生命周期本应该在;结束,所以c_str()指向的栈区会在作用域之外失效,为了延长其生命周期,我们通过右值引用和带const的左值引用,以及完全初始化string变量都可以延长其生命周期。
所谓延长其生命周期,也就是使得string有效访问,直到函数传递后不再访问string类型变量为止,由c++定义回收。否则,其string类型变量使用之后,内容再回收,异步的程序如果再次访问此栈区,可能会在某种情况下,被应用程序某个行为进行修改,从而导致此值的错误,然后从隐秘的bug变成实际出现的bug。
在工作中,通常我们身上挂着几十上百个bug,对应着十多个设备机器,如果每次都是人走过去调试非常不方便。如果是非界面的问题,我们可以通过ssh远程,如果是界面问题,我们只能通过vnc远程连接,但是vnc远程不是很方便,本文介绍一个更常用和方便的方法,novnc。基于此加速我们调试问题的节奏
安装
安装主要是安装Vino和novnc,默认机器可能已经预装了,对于没有预装的版本,可以如下
apt install novnc vino websockify
当然,如不想使用vino,那么tightvncserver也可以,但是本人更常用vino,本文介绍也通过vino
apt install tightvncserver
配置
对于vnc,我们需要默认打开一下配置,我们可以在控制面板里面选,那太麻烦了,人还是得过去一趟
所以下面介绍直接配置
ssh kylin@localhost gsettings set org.ukui.control-center vino-enabled true gsettings set org.gnome.Vino prompt-enabled false vncpasswd systemctl --user restart vino-server
上面配置就是打开了vnc的配置,这样远程可以通过vnc viewer进行连接,例如如下
接下来配置novnc就很简单了
kylin@kylin:~$ /usr/share/novnc/utils/launch.sh Using installed websockify at /usr/bin/websockify Starting webserver and WebSockets proxy on port 6080 WebSocket server settings: - Listen on :6080 - Web server. Web root: /usr/share/novnc - No SSL/TLS support (no cert file) - proxying from :6080 to localhost:5900
然后到自己编程的机器上,打开浏览器,登录网站http://${ip}:6080/vnc.html
就出现如下画面

点击连接,输入密码
浏览器正常登录vnc
多个机器就是多个浏览器网页页面而已。
总结
这里介绍了我平时多个bug同时调试的一种方法,用来提高自己解决问题效率。
mmu是arm64芯片上的一个内存管理单元,使用mmu的机制可以快速通过硬件将虚拟地址转换成物理地址,本文介绍crash工具的使用,可以比较方便解析内核的结构,故根据虚拟地址向物理地址转换的过程来梳理掌握crash工具的使用,并复习一下内存的基本知识。
机器环境
对于arm64机器的页表设置,每个机器的环境不一致,但是原理都是一致的,本文机器环境如下
- 39位地址
- 4k页大小
- 9bit页表项
- 三级页表
CONFIG_ARM64_VA_BITS_39=y CONFIG_ARM64_4K_PAGES=y CONFIG_PGTABLE_LEVELS=3
为了找到符合我机器的说明,我翻了很早的内核版本docs,可以参考信息如下
AArch64 Linux memory layout with 4KB pages + 3 levels: Start End Size Use ----------------------------------------------------------------------- 0000000000000000 0000007fffffffff 512GB user ffffff8000000000 ffffffffffffffff 512GB kernel Translation table lookup with 4KB pages: +--------+--------+--------+--------+--------+--------+--------+--------+ |63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0| +--------+--------+--------+--------+--------+--------+--------+--------+ | | | | | | | | | | | v | | | | | [11:0] in-page offset | | | | +-> [20:12] L3 index | | | +-----------> [29:21] L2 index | | +---------------------> [38:30] L1 index | +-------------------------------> [47:39] L0 index +-------------------------------------------------> [63] TTBR0/1
根据上面可以知道,当前环境最大内存大小是512GB,因为是三级页表,所以这里默认没有L0 index [47:39]。为了概念的统一,我这里将三级页表也叫做Level 1和Level 2和Level 3以及 in-page offset,同四级页表一个叫法。
关于页表的转换,手册默认是按照四级页表计算,如下图示
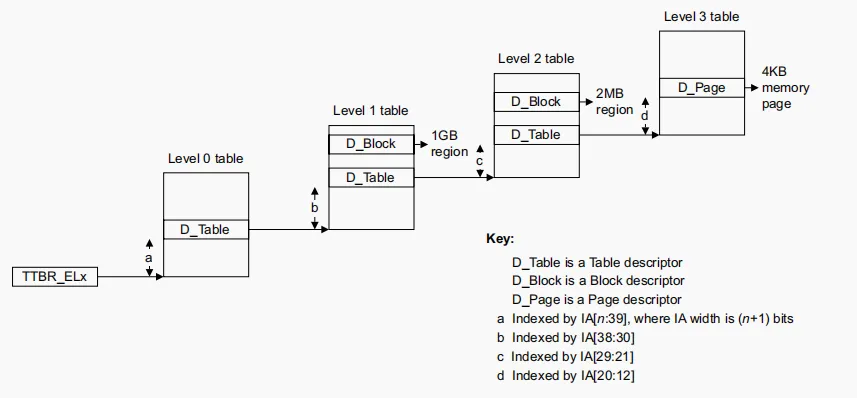
我们根据三级页表计算,下面开始演示。
以内核地址为例
为了拿到一个已经映射的地址,我们可以加载一个ko,用其中的数据地址,或者直接使用某个进程的task_struct内存地址,本文获取的是test.ko启动kthread的task_struct
5190 2 5 ffffff80c0002b80 RU 0.0 0 0 [spinlock_thread]
可以看到此task_struct地址是ffffff80c0002b80,下面开始转换
虚拟地址解析
对于上面的虚拟地址,我们按位可以解析如下

可以得到pgd_offset=3,pmd_offset=0,pte_offset=0xb80。并且我们知道其结构体大小如下
crash> struct pgd_t -x typedef struct { pgdval_t pgd; } pgd_t; SIZE: 0x8 crash> struct pud_t -x typedef struct { p4d_t p4d; } pud_t; SIZE: 0x8 crash> struct pmd_t -x typedef struct { pmdval_t pmd; } pmd_t; SIZE: 0x8 crash> struct pte_t -x typedef struct { pteval_t pte; } pte_t; SIZE: 0x8
可以看到,因为我们是64位系统,存放一个页表的size就是8,而我们页表换算的时候,是按照基地址+offset计算的,这个offset值的是多少个地址,而不是地址的size,所以我们获得基地址之后,计算下一级页表的存放物理地址的时候,应该乘上size,也就是8,因为实际存放这个64位地址要占用8个字节,那么这里我们就可以知道信息如下
- level1页表的offset是3,size就是0x18
- level2页表的offset是0,size就是0
- level3页表的offset是2,size就是0x10
- in-page offset 就是0xb80
TTBR1_EL1
我们获取的是内核的地址,那么其基地址来源于TTBR1_EL1,对于内核,其默认值存放在变量init_mm.pgd中,我们可以查看如下
crash> p init_mm.pgd $1 = (pgd_t *) 0xffffffc009eea000
我们可以根据这个基地址开始计算pgd
计算pgd
pgd的地址就是TTBR的地址 加上 pgd_offset * 8 ,所以得出如下
0xffffffc009eea018 = 0xffffffc009eea000 + 0x3 * 8
此时读取其值就是下一级页表的基地址
crash> rd ffffffc009eea018 -x ffffffc009eea018: 00000001ff20f003
值得注意的是,虚拟地址只是操作系统抽象的东西,所以存放的下一级页表的基地址是物理地址,不是虚拟地址,我们拿到地址 0x00000001ff20f003
对于arm64而言,内存不是恒等映射的,而是线性映射,也就是我们拿到的物理地址,其虚拟地址通常是 加上 ffffff8000000000 的offset 的线性映射的,所以我们拿到的地址0x00000001ff20f003 的虚拟地址是
0xffffff81ff20f003 = 0x00000001ff20f003 + 0xffffff8000000000
我们验证一下线性映射地址即可,如下
crash> ptov 0x00000001ff20f003 VIRTUAL PHYSICAL ffffff81ff20f003 1ff20f003
这里虚拟地址的bit [0:1] 用来表示是Block/Page,这里是3,也就是Page,我们寻找下一级页表。
计算pmd
pmd的地址是 对应的虚拟地址 去掉 bit0和bit1 后 加上 offset,这么说可能有点绕,转换计算公式如下
0xffffff81ff20f000 = 0xffffff81ff20f003 & ~0x3 + 0x0 * 8
然后读取其值即可获得下一级页表基地址的物理地址
crash> rd ffffff81ff20f000 -x ffffff81ff20f000: 00000001ff20e003
同样的,这里通过命令转换,当然也可以自己手动加上0xffffff8000000000的线性映射的offset。
crash> ptov 1ff20e003 VIRTUAL PHYSICAL ffffff81ff20e003 1ff20e003
这里看到还是3,说明不是Block,而是Page。
计算pte
pmd的地址计算和pud一致,如下
0xffffff81ff20e010 = 0xffffff81ff20e003 & ~0x3 + 0x2 * 8
此时读取下一级页表
crash> rd ffffff81ff20e010 -x ffffff81ff20e010: 00680000c0002707
这里我们接下来读的是pte的地址,0x00680000c0002707 具备upper attr和lower attr。关于页属性的描述如下
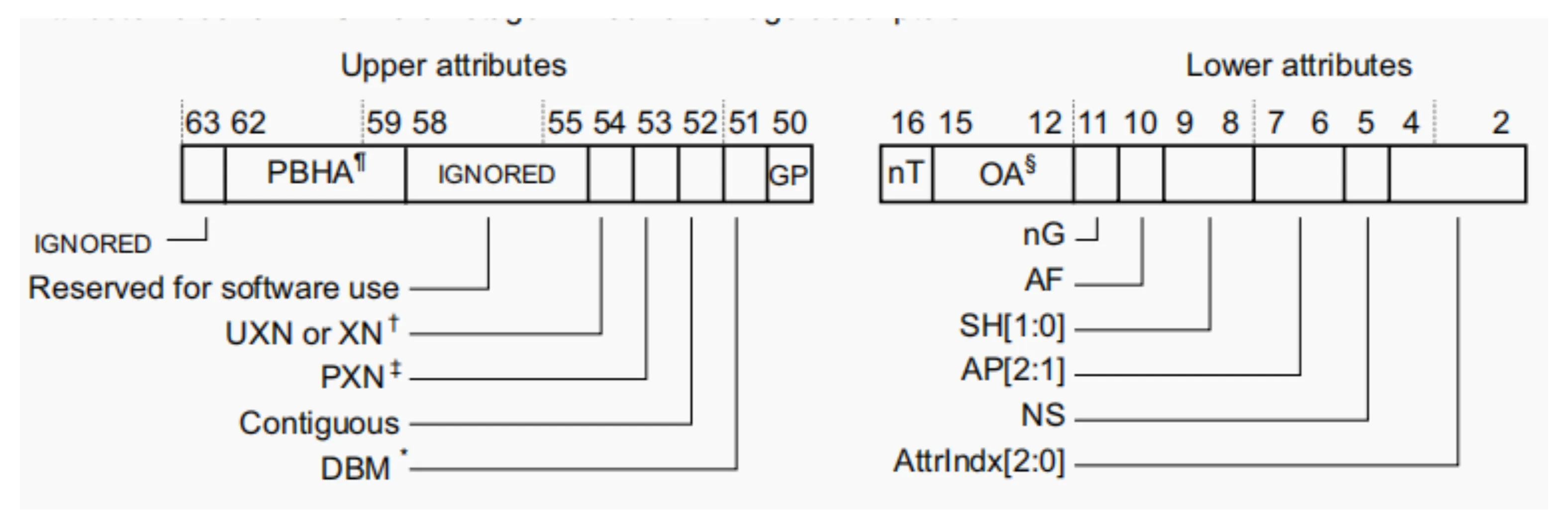
对于pte地址,其值是0x00680000c0002707,那么其属性值如下表示

除了属性值,其他部分就是物理页面基地址了,我们需要去掉属性值,提取物理页面基地址,那么如下
680000c0002707 & ~0xfff = 680000c0002000 # 去掉低12位 680000c0002000 & 0x7fffffffff = c0002000 # 去掉高25位
物理页
通过上面的pte地址,去掉属性之后,我们得到了物理页也就是0xc0002000,我们知道page-in offset是0xb80,那么真实的页就是
0xc0002b80 = 0xc0002000 + 0xb80
这里就计算出来了虚拟地址对于的物理页地址了。
同样的,在crash中,默认提供的vtop会自动帮我们计算,vtop的结果如下
crash> vtop ffffff80c0002b80 VIRTUAL PHYSICAL ffffff80c0002b80 c0002b80 PAGE DIRECTORY: ffffffc009eea000 PGD: ffffffc009eea018 => 1ff20f003 PMD: ffffff81ff20f000 => 1ff20e003 PTE: ffffff81ff20e010 => 680000c0002707 PAGE: c0002000 PTE PHYSICAL FLAGS 680000c0002707 c0002000 (VALID|SHARED|AF|PXN|UXN) PAGE PHYSICAL MAPPING INDEX CNT FLAGS ffffffff02e00080 c0002000 dead000000000400 0 0 0
可以看到,我们手动计算的地址转换过程和vtop提供的信息一样。
以用户地址为例
上面已经介绍过转换过程了,下面用户地址为例的转换就快速过一下。做个验证
测试代码
为了测试,提供一个简单的代码
#include <stdio.h> #include <unistd.h> char str[] = "hello kylin"; int main() { printf("vtop -c %d %p [%s] \n", getpid(), str, str); while(1); return 0; }
输出结果
我们拿到信息如下
vtop -c 13725 0x411038 [hello kylin] crash> vtop -c 13725 0x411038 VIRTUAL PHYSICAL 411038 8c2c3038 PAGE DIRECTORY: ffffff81f262b000 PGD: ffffff81f262b000 => 1f2c5a003 PMD: ffffff81f2c5a010 => 1f5fd0003 PTE: ffffff81f5fd0088 => e800008c2c3f43 PAGE: 8c2c3000 PTE PHYSICAL FLAGS e800008c2c3f43 8c2c3000 (VALID|USER|SHARED|AF|NG|PXN|UXN|DIRTY) VMA START END FLAGS FILE ffffff805b21a840 411000 412000 100873 /root/test PAGE PHYSICAL MAPPING INDEX CNT FLAGS ffffffff0210b0c0 8c2c3000 ffffff806d097b29 1 1 80014 uptodate,lru,swapbacked
此时知道了物理地址是0x8c2c3038,读取内容即可
crash> rd -8 -p 8c2c3038 16 8c2c3038: 68 65 6c 6c 6f 20 6b 79 6c 69 6e 00 00 00 00 00 hello kylin.....
一切正常,下面开始手动推导
手动推导页表转换
TTBR0_EL0
我们先获取基地址,对于进程,基地址在task_struct的struct_mm的pgd
crash> set 13725 PID: 13725 COMMAND: "test" TASK: ffffff81f0a09d00 [THREAD_INFO: ffffff81f0a09d00] CPU: 7 STATE: TASK_RUNNING (ACTIVE)
这里我们拿到了task_struct的地址是ffffff81f0a09d00,那么mm的值是0xffffff81f5fa2ec0
struct task_struct { [1160] struct mm_struct *mm; } crash> struct task_struct.mm ffffff81f0a09d00 -o struct task_struct { [ffffff81f0a0a188] struct mm_struct *mm; } crash> struct task_struct.mm ffffff81f0a09d00 -x mm = 0xffffff81f5fa2ec0
此时我们获得了进程的pgd地址如下
crash> struct mm_struct.pgd 0xffffff81f5fa2ec0 pgd = 0xffffff81f262b000
计算pgd
我们拿到地址是0xffffff81f262b000,此时虚拟地址是0x411038,计算如下
ffffff81f262b000 = ffffff81f262b000 + 0 crash> rd ffffff81f262b000 -x ffffff81f262b000: 00000001f2c5a003 crash> ptov 00000001f2c5a003 VIRTUAL PHYSICAL ffffff81f2c5a003 1f2c5a003
计算pmd
我们拿到地址0xffffff81f2c5a003,继续计算
ffffff81f2c5a010 = ffffff81f2c5a003 & ~0x3 + 0x2 * 8 crash> rd ffffff81f2c5a010 -x ffffff81f2c5a010: 00000001f5fd0003 crash> ptov 00000001f5fd0003 VIRTUAL PHYSICAL ffffff81f5fd0003 1f5fd0003
计算pte
我们拿到地址0xffffff81f5fd0003,最后计算pte
ffffff81f5fd0088 = ffffff81f5fd0003 & ~0x3 + 0x11 * 8 crash> rd ffffff81f5fd0088 -x ffffff81f5fd0088: 00e800008c2c3f43 crash> ptov 00e800008c2c3f43 VIRTUAL PHYSICAL e7ff808c2c3f43 e800008c2c3f43
计算物理地址
我们拿到了e800008c2c3f43的地址,需要去掉属性bit,计算可得
e800008c2c3f43 & ~0xfff = e800008c2c3000 # 去掉低12位 e800008c2c3f43 & 0x7fffffffff = 8c2c3000 # 去掉高25位
此时物理页起始是0x8c2c3000,对于数据的物理地址是
8c2c3038 = 8c2c3000 + 0x38
这样我们就计算出来物理页地址了,我们读取其内容验证一下
crash> rd -8 -p 8c2c3038 16 8c2c3038: 68 65 6c 6c 6f 20 6b 79 6c 69 6e 00 00 00 00 00 hello kylin.....
可以发现,其物理地址存放的内容正是我们设置的 "hello kylin"。 实验完成。
总结
根据上面的内容,我们通过物理地址和虚拟地址将页表的转换过了一遍,借助工具crash可以随时挂上内核的kcore进行调试判断,不会像gdb内核一样复杂并且不方便。
