目录
优先级调度算法顾名思义就是基于任务的优先级来进行调度,任何高优先级的任务都应该得到调度,本文介绍rtems的默认调度器算法优先级调度算法
一、基本数据结构
优先级调度算法默认是通过位图的方式实现O(1)的调度,其结构如下
typedef struct { /** * @brief Basic scheduler context. */ Scheduler_Context Base; /** * @brief Bit map to indicate non-empty ready queues. */ Priority_bit_map_Control Bit_map; /** * @brief One ready queue per priority level. */ Chain_Control Ready[ RTEMS_ZERO_LENGTH_ARRAY ]; } Scheduler_priority_Context;
这里面bitmap的结构体实现如下
typedef struct { /** * @brief Each sixteen bit entry in this word is associated with one of the * sixteen entries in the bit map. */ Priority_bit_map_Word major_bit_map; /** * @brief Each bit in the bit map indicates whether or not there are threads * ready at a particular priority. * * The mapping of individual priority levels to particular bits is processor * dependent as is the value of each bit used to indicate that threads are * ready at that priority. */ Priority_bit_map_Word bit_map[ 16 ]; } Priority_bit_map_Control;
根据上面两个数据结构,可以知道如下:
调度器的上下文,通过Base存储,如Lock和Processor_mask 位图来控制优先级,主优先级由major_bit_map来设置,次优先级通过bit_map来设置 位图的快速查找O(1)复杂度得益于aarch64的clz指令 根据位图计算的优先级值,每个值对应一个Ready的链表 Ready存放的就是最大256个优先级的链表 由数组和链表组成的拉链能够实现快速定位最高优先级任务
二、汇编CLZ
基于优先级的调度算法的快速查找优先级的核心是clz指令,该指令从最低位遇到1之前的计算0的个数。如下

rtems使用了gnu的内置函数版本,代码如下:
static inline unsigned int _Bitfield_Find_first_bit( unsigned int value ) { unsigned int bit_number; #if ( CPU_USE_GENERIC_BITFIELD_CODE == FALSE ) _CPU_Bitfield_Find_first_bit( value, bit_number ); #elif defined(__GNUC__) bit_number = (unsigned int) __builtin_clz( value ) - __SIZEOF_INT__ * __CHAR_BIT__ + 16; #else if ( value < 0x100 ) { bit_number = _Bitfield_Leading_zeros[ value ] + 8; } else { \ bit_number = _Bitfield_Leading_zeros[ value >> 8 ]; } #endif return bit_number; }
_Bitfield_Find_first_bit返回遇到1时0的个数
三、位图
对于位图的设置和更新,由于位图的特性,需要设置位图的major,然后根据major设置位图的minor。其代码如下
static inline void _Priority_bit_map_Add ( Priority_bit_map_Control *bit_map, Priority_bit_map_Information *bit_map_info ) { *bit_map_info->minor |= bit_map_info->ready_minor; bit_map->major_bit_map |= bit_map_info->ready_major; }
比较清晰的是major_bit_map的设置,它是直接赋值操作,而位图的minor应该由major的值来选择数组,所以需要在初始化中如下设置
函数_Priority_bit_map_Initialize_information
bit_map_info->minor = &bit_map->bit_map[ _Priority_Bits_index( major ) ];
这里可以看到,minor是取得bit_map→bit_map[x]的地址。
同样的,对于bitmap的remove,则很容易理解了,如下
static inline void _Priority_bit_map_Remove ( Priority_bit_map_Control *bit_map, Priority_bit_map_Information *bit_map_info ) { *bit_map_info->minor &= bit_map_info->block_minor; if ( *bit_map_info->minor == 0 ) bit_map->major_bit_map &= bit_map_info->block_major; }
需要注意的是,这里通过位与来清楚minor和major的值,那么有一个细节如下可以留意
mask = _Priority_Mask( major ); bit_map_info->ready_major = mask; bit_map_info->block_major = (Priority_bit_map_Word) ~mask; mask = _Priority_Mask( minor ); bit_map_info->ready_minor = mask; bit_map_info->block_minor = (Priority_bit_map_Word) ~mask;
这里我们位与的值实际上取反过了。所以位与可以达到清零的作用。
四、拉链
将数组和链表结合起来的拉链,其实现效果如下
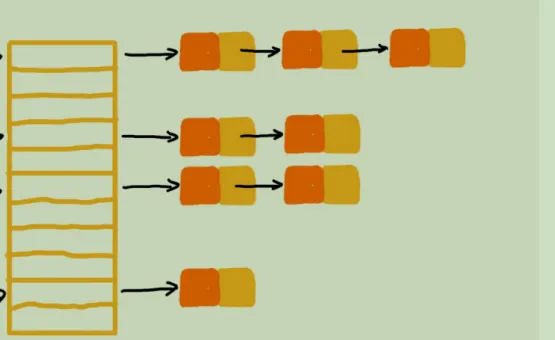
这里每个优先级对应一个数组,然后每个数组都是一个链表,链表通过队列的方式实现。也就是如下:
Chain_Control Ready[ RTEMS_ZERO_LENGTH_ARRAY ];
五、队列
管理基于优先级调度的方式是使用队列的方式,所有的插入操作都是尾插,所有的查询操作都是从头找。而链表的删除操作本身就是O(1)
则可以发现,队列实现的优先级链表的整体效率就是O(1)。代码如下
// 查找 static inline Chain_Node *_Chain_First( const Chain_Control *the_chain ) { return _Chain_Immutable_head( the_chain )->next; } // 插入 static inline void _Chain_Append_unprotected( Chain_Control *the_chain, Chain_Node *the_node ) { Chain_Node *tail; Chain_Node *old_last; _Assert( _Chain_Is_node_off_chain( the_node ) ); tail = _Chain_Tail( the_chain ); old_last = tail->previous; the_node->next = tail; tail->previous = the_node; old_last->next = the_node; the_node->previous = old_last; } // 删除 static inline void _Chain_Extract_unprotected( Chain_Node *the_node ) { Chain_Node *next; Chain_Node *previous; _Assert( !_Chain_Is_node_off_chain( the_node ) ); next = the_node->next; previous = the_node->previous; next->previous = previous; previous->next = next; #if defined(RTEMS_DEBUG) _Chain_Set_off_chain( the_node ); #endif }
六、调度器初始化
根据上面的分析,初始化调度器就是将bitmap和数组以及链表申请并清空即可。如下
void _Scheduler_priority_Initialize( const Scheduler_Control *scheduler ) { Scheduler_priority_Context *context = _Scheduler_priority_Get_context( scheduler ); _Priority_bit_map_Initialize( &context->Bit_map ); _Scheduler_priority_Ready_queue_initialize( &context->Ready[ 0 ], scheduler->maximum_priority ); }
_Priority_bit_map_Initialize将bit_map结构之间memset即可
_Scheduler_priority_Ready_queue_initialize遍历所有的Ready数组,对每个数组进行链表初始化,因为是单链表,所以如下
static inline void _Chain_Initialize_empty( Chain_Control *the_chain ) { Chain_Node *head; Chain_Node *tail; _Assert( the_chain != NULL ); head = _Chain_Head( the_chain ); tail = _Chain_Tail( the_chain ); head->next = tail; head->previous = NULL; tail->previous = head; }
七、调度器任务就绪
对于调度器的任务就绪,就是调用链表的插入,然后更新优先级的bitmap。那么对应函数如下
_Scheduler_priority_Ready_queue_update _Scheduler_priority_Ready_queue_enqueue
update的作用是初始化或更新bitmap,而enqueue的作用是将ready的链表节点移除,并且通过或操作设置bitmap。如下
static inline void _Scheduler_priority_Ready_queue_update( Scheduler_priority_Ready_queue *ready_queue, unsigned int new_priority, Priority_bit_map_Control *bit_map, Chain_Control *ready_queues ) { ready_queue->current_priority = new_priority; ready_queue->ready_chain = &ready_queues[ new_priority ]; _Priority_bit_map_Initialize_information( bit_map, &ready_queue->Priority_map, new_priority ); } static inline void _Scheduler_priority_Ready_queue_enqueue( Chain_Node *node, Scheduler_priority_Ready_queue *ready_queue, Priority_bit_map_Control *bit_map ) { Chain_Control *ready_chain = ready_queue->ready_chain; _Chain_Append_unprotected( ready_chain, node ); _Priority_bit_map_Add( bit_map, &ready_queue->Priority_map ); }
八、调度器任务阻塞
任务阻塞和就绪是相反的作用,先通过_Scheduler_priority_Ready_queue_extract将就绪队列的任务删除,如果就绪队列只有一个元素,则更新bitmap,清空bitmap设置,如下
static inline void _Scheduler_priority_Ready_queue_extract( Chain_Node *node, Scheduler_priority_Ready_queue *ready_queue, Priority_bit_map_Control *bit_map ) { Chain_Control *ready_chain = ready_queue->ready_chain; if ( _Chain_Has_only_one_node( ready_chain ) ) { _Chain_Initialize_empty( ready_chain ); _Chain_Initialize_node( node ); _Priority_bit_map_Remove( bit_map, &ready_queue->Priority_map ); } else { _Chain_Extract_unprotected( node ); } }
九、调度器任务调度
任务调度的操作就是从ready队列取出最高优先级任务出来,然后标记执行,对应函数为_Scheduler_priority_Get_highest_ready
static inline Thread_Control *_Scheduler_priority_Get_highest_ready( const Scheduler_Control *scheduler ) { Scheduler_priority_Context *context = _Scheduler_priority_Get_context( scheduler ); return (Thread_Control *) _Scheduler_priority_Ready_queue_first( &context->Bit_map, &context->Ready[ 0 ] ); }
_Scheduler_priority_Ready_queue_first的作用就是在队列中取出head头节点。
十、调度器任务优先级更新
优先级更新的操作有如下四步
先将原任务从就绪队列取出 根据新的任务设置就绪队列和bitmap 如果bitmap存在,则追加的方式将此任务入队 如果bitmap不存在,则初始化就绪队列 代码实现如下
_Scheduler_priority_Ready_queue_extract( &the_thread->Object.Node, &the_node->Ready_queue, &context->Bit_map ); _Scheduler_priority_Ready_queue_update( &the_node->Ready_queue, unmapped_priority, &context->Bit_map, &context->Ready[ 0 ] ); if ( SCHEDULER_PRIORITY_IS_APPEND( new_priority ) ) { _Scheduler_priority_Ready_queue_enqueue( &the_thread->Object.Node, &the_node->Ready_queue, &context->Bit_map ); } else { _Scheduler_priority_Ready_queue_enqueue_first( &the_thread->Object.Node, &the_node->Ready_queue, &context->Bit_map ); }
十一、总结 至此,我们可以知道优先级调度算法是基于bitmap和队列实现的一种调度算法,此调度算法通过计算任务优先级来调整任务。整体效率是O(1)。
对于该调度算法而言,其是可抢占性的,并且任务是具备队列的FIFO特性的。