目录
随着AI智能的发展,继传统的CPU和GPU之后,又推出了许多更适用于AI学习的芯片,本文就NPU芯片如何在RK平台提供的SDK基础上开发做一个介绍。
一、NPU芯片简介
NPU全称为Neural network Processing Unit,即神经网络处理器。
二、RKNN使用方法
1.SDK下载及内容介绍
可以在110服务器获取 /home/develop/rk/project/Rockchip_RK356X_RKNN_SDK_V0.7.0_20210402
这里 RKNN_API_for_RK356X 里面主要包含了linux和android系统对于如何使用模型文件调用NPU进行AI运算的demo。
rknn-toolkit 是用于将其他神经网络训练架构模型如何转化为 rknn 架构模型的demo,它分为了docker和nodocker版本,建议使用docker版,因为nodeocker版本对于python-3和pip软件版本的要求比较严格,环境不太好搭建。
2.rknn-toolkit 工具使用
这里我使用含docker版本举例。
- 首先进入rknn-toolkit2-0.7.0/docker/ 文件夹
- 可以看到 rknn-toolkit2-0.7.0-docker.tar.gz 镜像文件
- 使用 sudo docker load --input rknn-toolkit2-0.7.0-docker.tar.gz 命令加载镜像
- 加载成功后,可以使用 sudo docker images 命令确认。
正常加载后,就可以进入docker环境 如下,
docker run -t -i --privileged -v /home/kylin/:/home/kylin/ rknn-toolkit2:0.7.0 /bin/bash
执行后命令行的前缀会改变。
进入docker环境后,进入 rknn-toolkit2-0.7.0/examples/ 目录下,可以看到包含了一些以比较常见的神经网络训练框架命名的文件夹。
这里我们以caffe为例,将 caffemodule 转换为 rknnmodule。
进入 caffe/vgg-ssd/ 文件夹,其是转换 caffemodule 的一个demo 。里面使用了 deploy_rm_detection_output.prototxt 文件中提供的图层模型,把 caffemodule 通过 rknn.api 转换为了 rknnmodule 。重点包含以下几个函数:
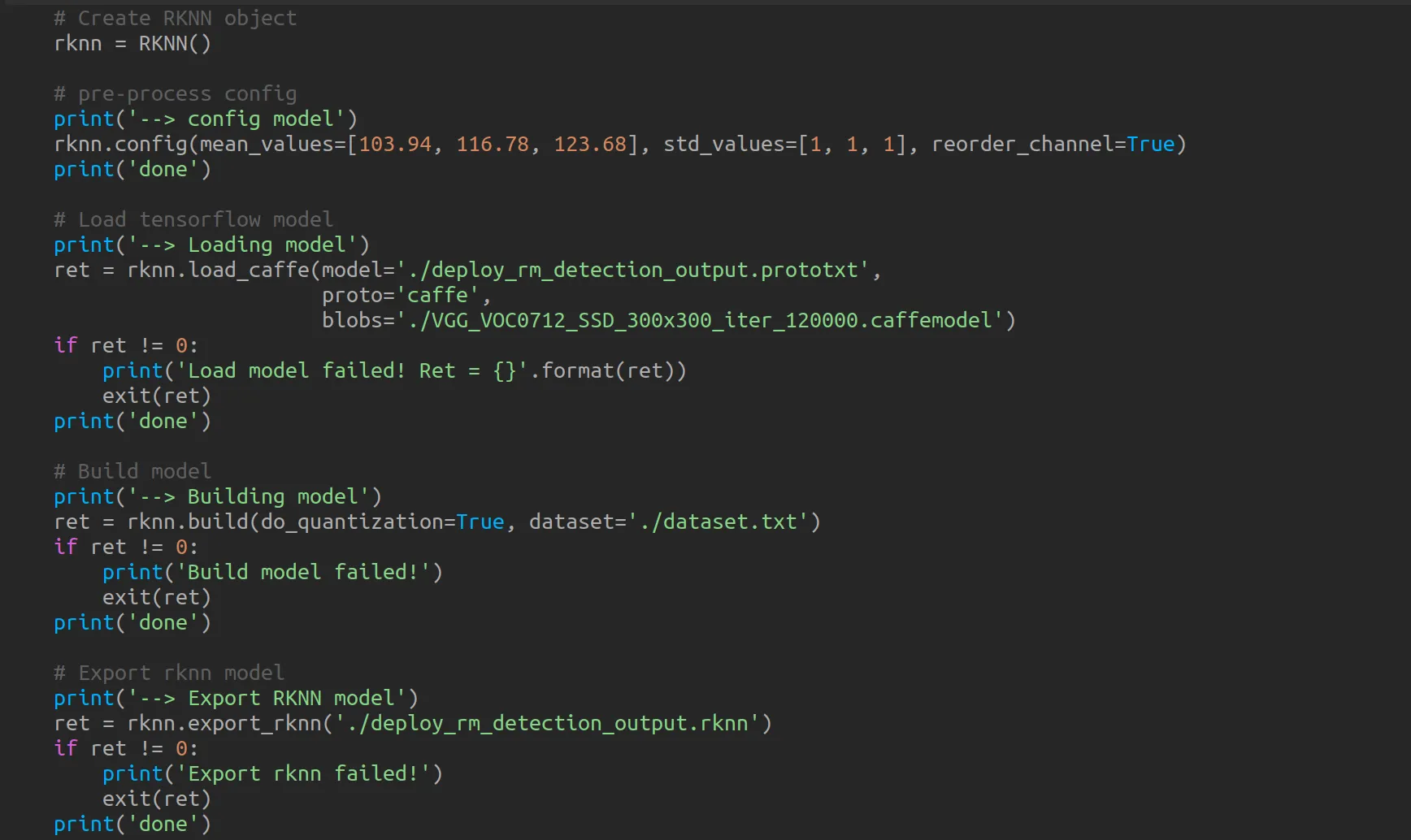
 可以看到流程和RK给出的文档中一致,按照步骤操作即可。
可以看到流程和RK给出的文档中一致,按照步骤操作即可。
这里会需要一个 caffemodule 的训练模型,可以通过
https://eyun.baidu.com/s/3jJhPRzo , password is rknn
进行下载。
然后执行 python test.py 运行脚本,执行成功后就可以看到文件夹中多了 .rknn 为后缀的文件,它就是rk平台的模型。
这里就完成了模型的转换,过程中可能会根据模型效率/准确度的需求修改一些参数,可以参考SDK中的文档进行调整。
3.RKNN模型使用
上面我们已经得到了后缀为 .rknn 的模型文件,现在我们就来讲解如何在RK平台使用模型通过NPU进行图像的解析操作。其实上面在转换模型时已经使用python脚本进行了图像解析的示例,本章介绍demo中通过C语言调用RKNN接口的过程。
进入 RKNN_API_for_RK356X_v0.7_20210402/examples/rknn_ssd_demo/ 文件夹,可以看到
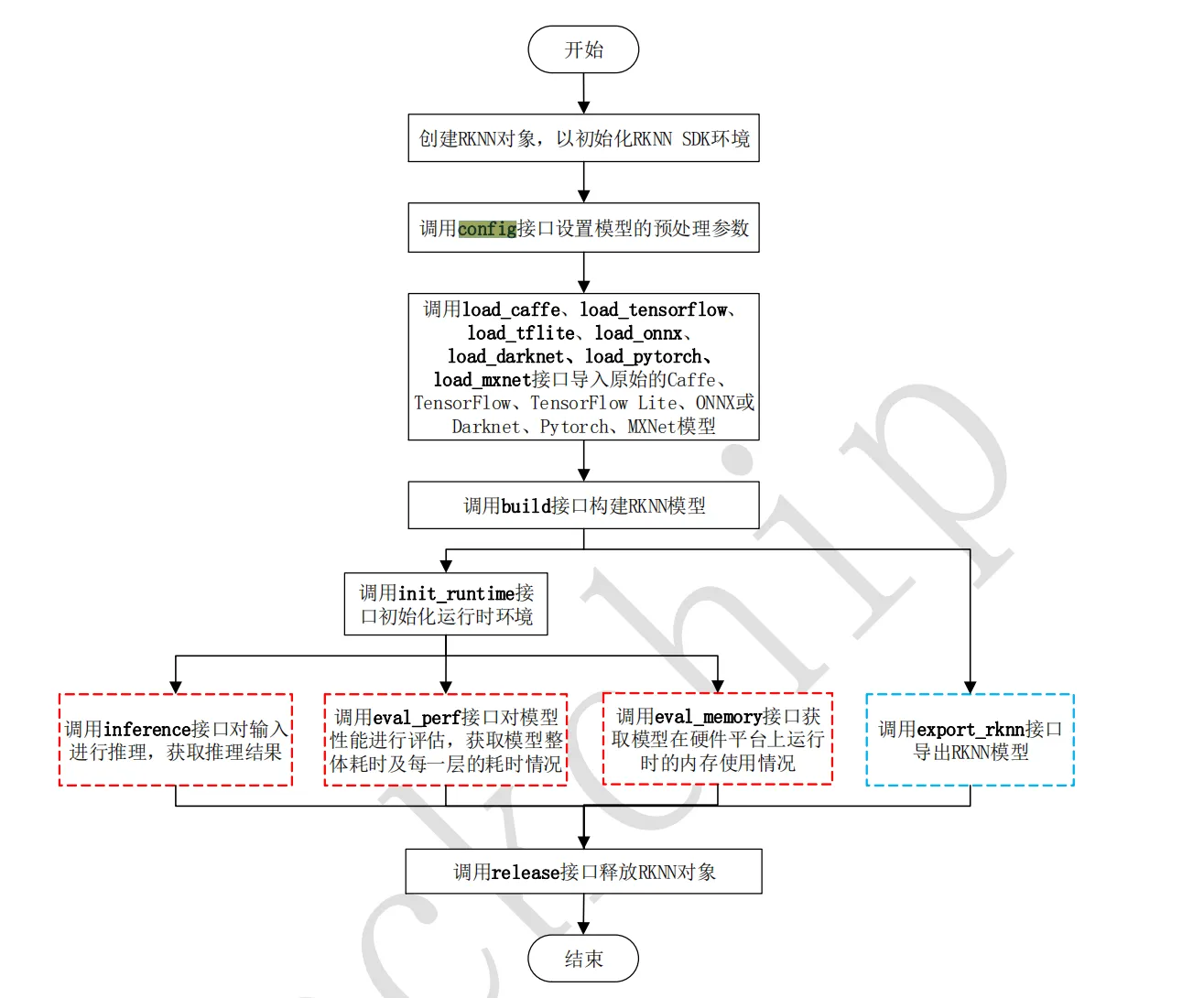
我们先看看源码调用流程
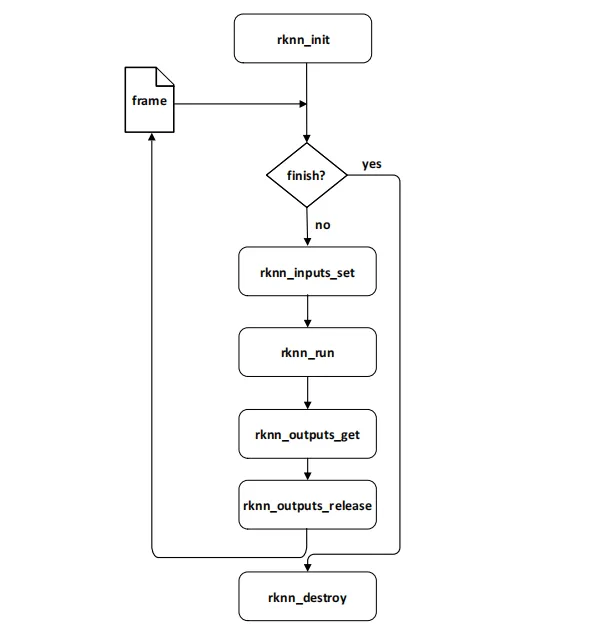 跟文档流程一致,其中多了一步 postProcessSSD ,这是将结果中的值转换为图片中的坐标点,用于后面画框所用。
跟文档流程一致,其中多了一步 postProcessSSD ,这是将结果中的值转换为图片中的坐标点,用于后面画框所用。
 看完了源代码我们可以编译应用。这里的环境是rk3568开发板+麒麟v10系统,所以直接执行
看完了源代码我们可以编译应用。这里的环境是rk3568开发板+麒麟v10系统,所以直接执行 build-linux.sh 脚本。
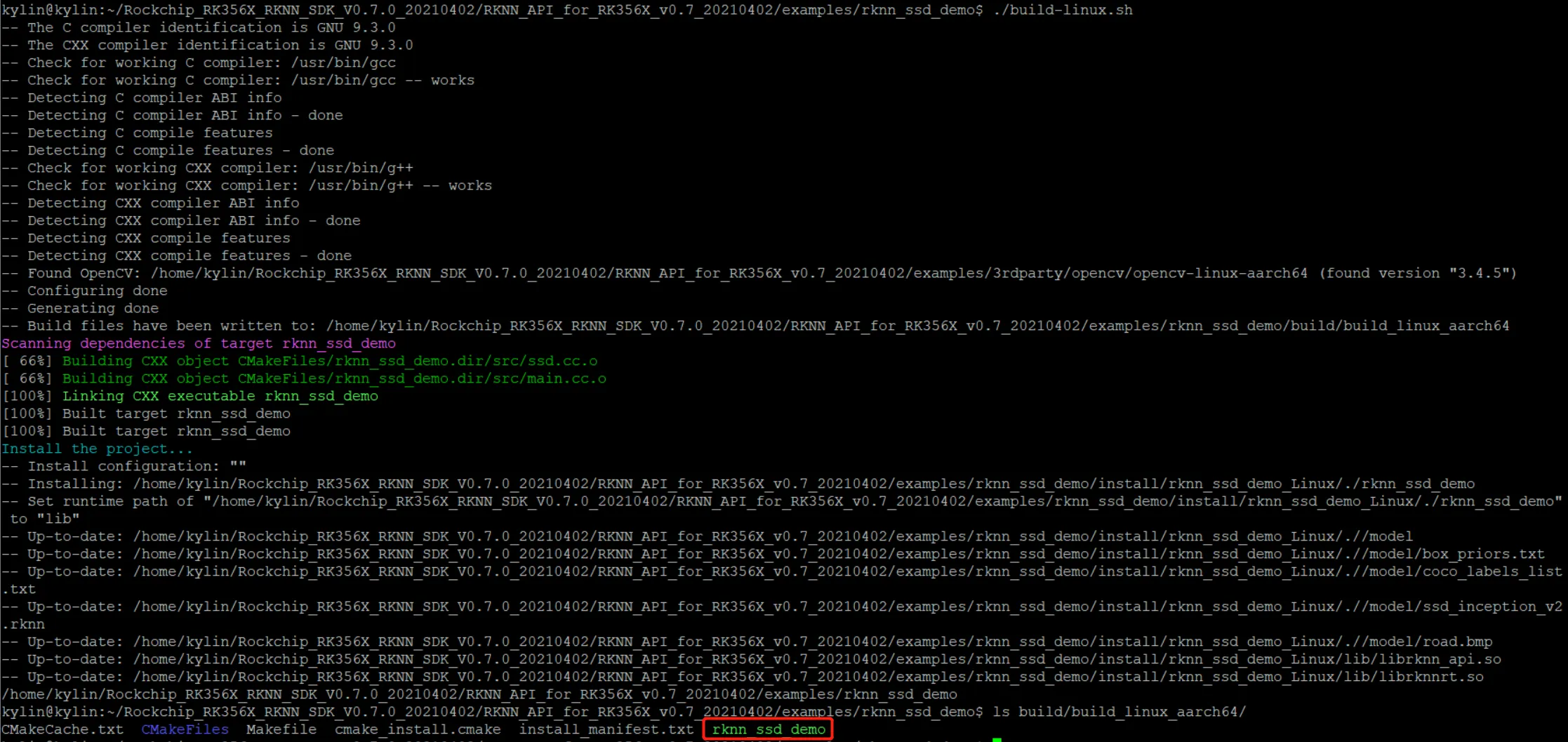 完成后可以看到生成了 rknn_ssd_demo 的二进制文件,接下来我们使用它看看效果。
完成后可以看到生成了 rknn_ssd_demo 的二进制文件,接下来我们使用它看看效果。
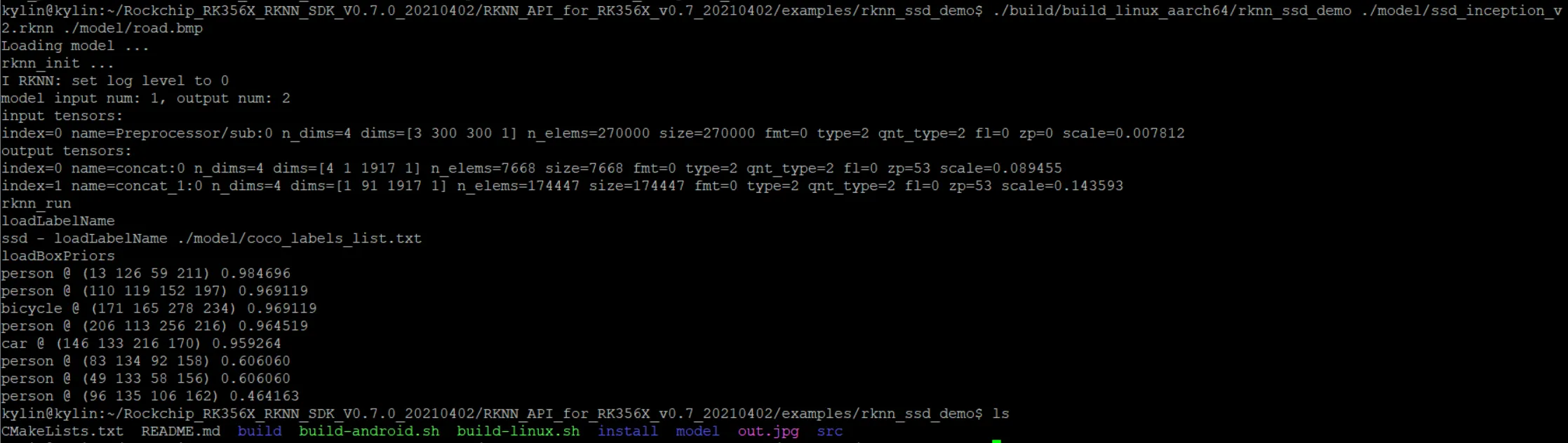 执行
执行
./build/build_linux_aarch64/rknn_ssd_demo ./model/ssd_inception_v2.rknn ./model/road.bmp
第一个参数是我们生成的二进制文件
第二个参数是 .rknn 为后缀的module模型文件
第三个参数是要被检测的图片。执行后在本地文件夹中生成了 out.jpg 图片
输出如下

 可以看到,模型在上图中成功识别到了行人和车辆的位置。
可以看到,模型在上图中成功识别到了行人和车辆的位置。
三、NPU硬件信息查看
如何判断是否调用到了NPU去处理的上面图像呢。我们可以通过中断:
 如果调用到NPU,中断号会增加。
如果调用到NPU,中断号会增加。
内核中还提供了调整NPU频率的接口:
 查看NPU支持的模式,默认为 simple_ondemand
查看NPU支持的模式,默认为 simple_ondemand
 查看NPU当前的频率
查看NPU当前的频率
echo performance > /sys/devices/platform/fde40000.npu/devfreq/fde40000.npu/governor
调整NPU的工作模式为性能模式(保持最大频率)
 查看NPU当前工作状态,@之前为占用率,之后为当前频率
查看NPU当前工作状态,@之前为占用率,之后为当前频率
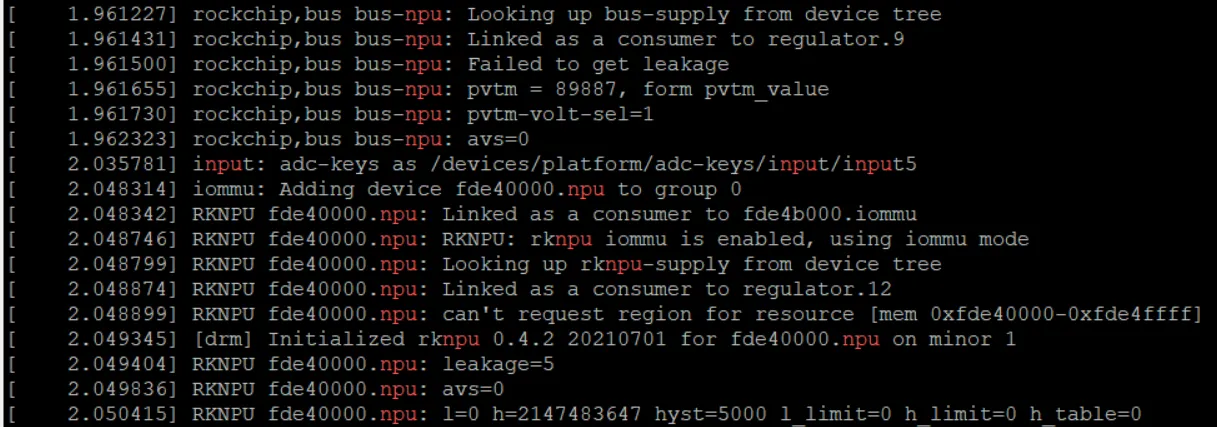 根据内核log,可以判断NPU是否被加载成功,从中也可以看出NPU包含了iommu模块,对内存读写进行了优化。
根据内核log,可以判断NPU是否被加载成功,从中也可以看出NPU包含了iommu模块,对内存读写进行了优化。