之前的内容已经能够在基于开源组件mosquitto 来进行mqtt的演示和利用了,但是一个产品功能并不是简单使用使用就完事儿了,所以需要开发。 而开发又分为两部分: 一个是协议栈开发,也就是针对官方协议文档去实现这份协议框架 另一个是应用开发,也就是针对协议栈进行产品应用场景的代码开发
这里我从网上找到了别人开发好的协议栈源码(cMQTT),在借助他人源码的基础之上,开发一个简单的应用程序,实现上述开源组件发布和订阅的基本功能,然后在此基础上衍生,大家一起探讨探讨,如何自己开发这个MQTT协议栈。
拉代码
git clone https://github.com/YorkJia/cMQTT.git
配置和编译
./confgure.sh && make install
这时候就会出现libcMQTT.so。这就可以利用它,去简单的编写一些代码了
编写发布者程序
- 创建文件
touch simple_pub.c
- 写个小例子
int main(int argc, char *argv[]) { int res, loop_cnt = 0, cnt = 0; mqtt_client_t *pclient = NULL; pclient = mqtt_client_new("127.0.0.1", 1883, NULL, "client/01", "kylin", "qwe123"); mqtt_set_will_opt(pclient, MQTT_QOS0, 0, "test/a", NULL); do{ printf("try to connect broker...\n"); res = mqtt_client_connect(pclient); sleep(1); }while(res != SUCCESS_RETURN); while (1) { example_publish(pclient, "Hello World"); mqtt_client_yield(pclient, 1000); } mqtt_client_close(pclient);} int example_publish(mqtt_client_t *pclient, char* data) { char payload[100]; if(pclient == NULL){ return FAIL_RETURN; } memset(payload, 0, sizeof(payload)); sprintf(payload, data); mqtt_publish_simple(pclient, "test/a", MQTT_QOS0, payload, strlen(payload)); }
- 开始编译
gcc simple_pub.c -I ../../infra/ -I ../../mqtt/ -L ../../ -lcMQTT -lpthread -o simple_pub
- 测试
mosquitto_sub -h 127.0.0.1 -t "test/a" -u kylin -P qwe123 ./simple_pub
可以看到mosquitto能够正常接收到hello world字串

至此,一个最简单的发布者代码已经编译完成了
编写订阅者程序
- 创建文件
touch simple_sub.c
- 写个小例子
int main(int argc, char *argv[]) { int res, loop_cnt = 0, cnt = 0; mqtt_client_t *pclient = NULL; pclient = mqtt_client_new("127.0.0.1", 1883, NULL, "client/02", "kylin", "qwe123"); mqtt_set_will_opt(pclient, MQTT_QOS0, 0, "test/a", NULL); do{ printf("try to connect broker...\n"); res = mqtt_client_connect(pclient); sleep(1); }while(res != SUCCESS_RETURN); while (1) { res = mqtt_subscribe(pclient, "test/a", MQTT_QOS0, example_message_arrive, NULL); if(res < 0){ printf("subscribe[%s] fail.\n", "test/a"); } mqtt_client_yield(pclient, 1000); } mqtt_client_close(pclient); } void example_message_arrive(void *pcontext, void *pclient, mqtt_event_msg_t *msg) { mqtt_topic_info_t *topic_info = (mqtt_topic_info_t *)msg->msg; switch (msg->event_type) { case IOTX_MQTT_EVENT_PUBLISH_RECEIVED: /* print topic name and topic message */ printf("Message Arrived:\n"); printf("Topic : %.*s\n", topic_info->topic_len, topic_info->ptopic); printf("Payload: %.*s\n", topic_info->payload_len, topic_info->payload); break; default: break; } }
- 编译
gcc simple_sub.c -I ../../infra/ -I ../../mqtt/ -L ../../ -lcMQTT -lpthread -o simple_sub
- 测试 借用之前命令来发布主题消息
./simple_sub mosquitto_pub -h localhost -V mqttv31 -t 'test/a' -u kylin -P qwe123 -i "c3" -m "Hello World" -M 0
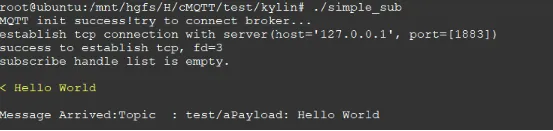
至此,一个最简单的订阅者代码已经编译完成了
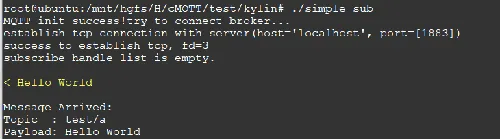
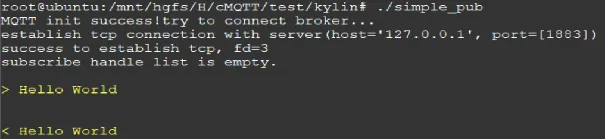
将简单发布者和简单订阅者运行起来
- 运行Broker
mosquitto -c /etc/mosquitto/mosquitto.conf -d
- 运行示例程序
./simple_sub ./simple_pub
协议栈开发
说起协议栈的开发,与应用开发相比,一般都会是一个比较大的工程。就好像做菜。 应用开发者就好比去菜市场买菜,回家烹饪(或者点个外卖)。 协议栈开发者就好比从菜种子开始种,直到成熟后,再摘菜回家烹饪。
此文章不讨论实现MQTT的细节和展示协议栈实现的具体代码。而是和大家一起讨论讨论,怎么给菜园子松松土,把种子播进去。
代理(Broker)
从协议来看,代理的职责是接收订阅者的请求,将消息发送给订阅者,接收发布者的消息。 所以实现代理的方式应该大致如下:

其中,发布者和订阅者都是通过连接的方式接入Broker,epoll负责接收所有的事件数据,并解析和转发响应数据
订阅者
从协议来看,订阅者的职责是:设置QoS质量,选择需要订阅的主题,并将其封装成报文发送给代理去解析。然后回调接收订阅的消息。 所以实现订阅者的方式应该大致如下:

其中,回调处理主要为业务处理逻辑,如获取的温度,湿度,亮度等信息需要如何处理。 封装和解析的报文包括:CONNECT,CONNACK,SUBSCRIBE,SUBACK,UNSUBSCRIBE,UNSUBACK,PINGREQ,DISCONNECT
发布者
从协议来看,发布者的职责是:设置QoS质量,选择需要订阅的主题,并将其封装成报文发送给代理去解析。而发布者同时也可做订阅者,所以也可以回调接收订阅的消息 所以实现发布者(仅发布)的方式应该大致如下:

封装和解析的报文包括: CONNECT,CONNACK,PUBLISH,PUBACK,PUBREC,PUBREL,PUBCOMP,PINGREQ,DISCONNECT
协议特性
这里列举需要实现的协议特性:
1.主题设置:合理的设置主题和判断主题
2.主题过滤器:合理的使用通配符
3.会话管理:Broker合理的管理和调度众多的会话连接
4.保持连接:合理的判断连接是否持续
5.临终遗嘱:合理的执行遗嘱内容,包括主题,消息
6.响应:合理的设置响应,如服务端在合理的时间内收不到connect报文,应该主动管理会话
7.Qos等级:合理的运用QoS设置报文发送方式
8.清理会话:合理的保留和遗弃上一次会话的消息
9.保留消息:合理的判断是否保留上一次发送的消息
总结
至此,我们演示了MQTT的应用场景,我们既需要基于MQTT开发应用,又需要根据MQTT定制协议
本文基于物联网来介绍一下MQTT
MQTT是什么?
MQTT:MQ Telemetry Transport,消息队列遥测传输协议。 它是非常轻量的消息传递协议,对于与需要较小代码占用和/或网络带宽非常宝贵的远程位置建立连接,它最有用。 MQTT是分布式的软总线,它的消息通过订阅者,发布者,消息代理三个角色实现,它能存在于所有的智能设备上。从而达到万物互联。当然实现物联网的物联网协议也很多,如CoAP,HTTP,UPnP,XMPP等,但MQTT具有更加简单,轻量的优势。
MQTT名词解释
- 订阅者(Subscriber)
就是消息的接收者,设备需要消息,就从消息代理获取发布者推送的消息 - 发布者(Publisher)
就是消息的发送者,它能提供给消息代理特定含义的消息 - 消息代理(Broker)
就是接收订阅者和发布者的请求和消息,并根据请求转发消息 - 主题(Topic)
就是发布者用于标识发布什么类型的消息,订阅者用于标识订阅什么类型的消息 - QoS
就是用于确定发布者发布消息的等级,主要包括三个等级 qos0:表示未知服务,代表此消息最多发送一次,且不保证订阅者是否能够成功接收 qos1:表述已知服务,代表此消息发布后,需要得到至少一个订阅者的确定收到的回复,否则消息将被重发 qos2:表述保证服务,代表此消息发布后,不仅需要得到订阅者的回复,还会在收到订阅者回复后,再发送回复消息给订阅者确定。从而保证消息是完全稳定可靠的 - 临终遗嘱(Last Will and Testament) 就是当连接是异常断开的情况下,消息代理会按照发布者的临终遗嘱发送一条预设的消息。
- 保留消息(Retained)
就是当订阅者订阅消息时,判断是否打开保留消息从而决定是否立即发送上一条消息给订阅者 - 树形结构(Tree Struct)
就是指主题的分类按照树形结构分类,如卧室温度消息的结构为“home/houseroom/temperature” - 通配符(+/#)
就是可以通过通配符找到符合正则表达的所有主题,如 “home/houseroom/#”表示订阅所有卧室消息 “home/+/temperature”表示订阅所有房间的温度消息 - 清理会话(CleanSession)
如果置位为0,已断开过的服务端必须基于当前会话状态恢复新的客户端连接 如果置位为1,必须丢弃之前的任何会话,并开始新的会话 - 客户端(Client)
客户端包括订阅者和发布者,它会总是连接到MQTT服务器。 客户端可以:
- (1)发布其他客户端可能会订阅的信息。
- (2)订阅其它客户端发布的消息。
- (3)退订或删除应用程序的消息。
- (4)断开与服务器连接。
- MQTT服务器
服务器就是消息代理Broker,它可以是一个应用程序,也可以是设备。它位于发布者和订阅者之间 服务器可以:
- (1)接受来自客户的网络连接;
- (2)接受客户发布的应用信息;
- (3)处理来自客户端的订阅和退订请求;
- (4)向订阅的客户转发应用程序消息。
- 保持连接(Keep Alive)
就是指在客户端传输完成一个控制报文的时刻到发送下一个报文的时刻,两者最大允许的时间间隔。客户端需要保证控制报文发送时间不超过这个值。
消息发送
QoS0方式消息发送如下

QoS0级别的消息发送,意味着接收者并不会响应消息,发送者也不会做重试判断,所以消息最多可能送达一次,但也有可能无法送达
发送者:
发送这个 PUBLISH报文
接收者:
接收这个PUBLISH报文
QoS1方式发送

QoS1级别的消息发送,意味着消息至少被发送一次,并确定至少送达一次
发送者:
必须在每个新的消息上分配一个报文标识符,发送的PUBLISH报文必须标识为QoS=1,DUP=0,且必须将这个报文当作未确认的报文,直到接收到对应的响应报文
接收者:
响应PUBACK报文必须包含一个报文标识符,需要与接收到的PUBLISH报文相同
发送PUBACK报文后,接收者必须将任何包含相同报文标识符的PUBLISH报文当作一个新的消息。保证下一次仍能正常接收。
QoS2方式发送

QoS2是最高级别的发送方式,他确保消息不被丢失,同时也确保消息不重复。
发送者:
1.为消息分配一个未使用的报文标识符,然后将PUBLISH报文的标识符为置为QoS2 DUP0。
2.在发送PUBLISH报文时,将PUBLISH报文看作是未被确认的,直到收到PUBREC报文。且在收到PUBREC报文后必须发送一个PUBREL报文,该报文必须和PUBLISH报文具有相同的报文标识符。
3.同时,也必须将这个PUBREL报文看作是未确认的,直到从接收者那里收到对应的PUBCOMP报文。
4.最后,一旦发送了对应的PUBREL报文,就不能重发这个PUBLISH报文。
接收者:
1.响应的 PUBREC 报文必须包含报文标识符,这个标识符来自接收到的、已经接受所有权的PUBLISH 报文。
2.在收到对应的 PUBREL 报文之前,接收者必须发送 PUBREC 报文确认任何后续的具有相同标识符的 PUBLISH 报文。 在这种情况下,它不能重复分发消息给任何后续的接收者。
3.响应 PUBREL 报文的 PUBCOMP 报文必须包含与 PUBREL 报文相同的标识符。
4.发送 PUBCOMP 报文之后,接收者必须将包含相同报文标识符的任何后续 PUBLISH 报文当作一个新的发布。
测试验证
在Linux环境上体验体验MQTT
- 安装mosquitto
apt update && apt install mosquitto mosquitto-clients
- 创建认证文件
touch /etc/mosquitto/pwfile
创建用户和密码
mosquitto_passwd /etc/mosquitto/pwfile kylin
密码 qwe123
- 设置ACL规则
vim /etc/mosquitto/aclfile user kylin topic write test/# topic read test/#
- 启动消息代理(Broker)
mosquitto -c /etc/mosquitto/mosquitto.conf -d
- 订阅一个主题
mosquitto_sub -h localhost -t "test/a" -u kylin -P qwe123 -i "c1" -h 为指定mqtt的host地址 -t 为指定mqtt的主题 -u 为用户 -P 为密码 -i 为process id
- 发布一个主题
mosquitto_pub -h localhost -V mqttv311 -t 'test/a' -u kylin -P qwe123 -i "c3" -m "Hello World" -M 0 其中-h -t -u -i -P 意义与上一致 -V 指定发布消息的版本(mqttv311/mqttv31) -m 为发布的消息字符串 -M 为指定QoS等级
使用tcpdump抓数据包

如上图可以看到,在订阅者这里会阻塞轮询消息,直到发布者发送消息,订阅者就能收到消息“Hello World”
那么,随即而来就会产生一个疑问。之前将了这么多概念,那实际上这是怎么实现的呢?
探索如何实现这个事情,就需要利用tcpdump了
TCP抓包:
tcpdump -i lo tcp port 1883 -X
-i: 代表网络接口
tcp: mqtt是基于tcp传输的
port 1883: mqtt默认传输端口为1883
-X:在抓包时,以十六进制和 ASCII 表示打印每个数据包的数据
上面为完整的数据包内容,鉴于TCP有三次握手,所以取第四个数据包来简单解析MQTT数据包。如下

因为这是一个完整的TCP数据包,所以需要去掉一些TCP协议相关的数据 其中
4500 0053 8998 4000 4006 b30a 7f00 0001 7f00 0001 :为TCP的报文头。不具体分析 ae80 075b 6e6a c507 dded ec9e 8018 0200 fe47 0000 0101 080a 265c 053f 265c 053f :传输控制协议报文信息。不具体分析 101d 0004 4d51 5454 04c2 003c 0002 6333 0005 6b79 6c69 6e00 0671 7765 3132 33 :为真正的TCP数据包,也就是MQTT的数据包。主要分析这块数据
分析MQTT数据包
101d: 0x10由协议表:2.2.1可以查到,对应CONNECT,0x1d为字节长度,这里计算为29个字节

0004 4d51 5454 04c2 003c:
0004 :协议名字长度为4
4d51 5454:名字为MQTT(ASCII码)(如果是3.1协议,则字串为MQIsdp(4d51 4973 6470),长度为6)
04:版本号:3.1.1版本号为4, 3.1版本号为3。
c2:连接标志,包含:名称,密码,QoS0,清理会话。(3.1.2.3章节)

003c:保持连接时间,默认为60秒。超时情况下会发送PINGREQ报文用于探测broker和client(发布者和订阅者)直接是否仍在线(3.1.2.10章节)

0002 6333: 0002为Client ID 长度为2,6333 ID为字符串c3(也就是process ID),我发布的时候用-i参数指定了c3
0005 6b79 6c69 6e00 0671 7765 3132 33: 这里为账户kylin 密码 qwe123的字符串明文
总结
至此,一个完整的connect包已经解析完成了。在connect之后,其实后面还有许多数据包都能进行解析。
之前我们讨论了EDF调度器的实施策略,在rtems上,我们可以通过修改测试程序来演示一下edf调度器对任务调度的现象。
测试代码
为了能够开始测试代码,我们需要首先创建三个任务,如下
Task_name[ 1 ] = rtems_build_name( 'T', 'A', '1', ' ' ); Task_name[ 2 ] = rtems_build_name( 'T', 'A', '2', ' ' ); Task_name[ 3 ] = rtems_build_name( 'T', 'A', '3', ' ' ); for ( index = 1 ; index <= 3 ; index++ ) { status = rtems_task_create( Task_name[ index ], 1, RTEMS_MINIMUM_STACK_SIZE, RTEMS_DEFAULT_MODES, RTEMS_DEFAULT_ATTRIBUTES, &Task_id[ index ] ); directive_failed( status, "rtems_task_create loop" ); } for ( index = 1 ; index <= 3 ; index++ ) { status = rtems_task_start( Task_id[ index ], Task_1_through_3, index ); directive_failed( status, "rtems_task_start loop" ); }
3个任务都运行了函数Task_1_through_3,我们可以查看Task_1_through_3函数的实现如下
rtems_task Task_1_through_3( rtems_task_argument argument ) { rtems_id rmid; rtems_id test_rmid; rtems_time_of_day time; rtems_status_code status; int start = 0; status = rtems_rate_monotonic_create( argument, &rmid ); directive_failed( status, "rtems_rate_monotonic_create" ); status = rtems_rate_monotonic_ident( argument, &test_rmid ); directive_failed( status, "rtems_rate_monotonic_ident" ); if ( rmid != test_rmid ) { printf( "RMID's DO NOT MATCH (0x%" PRIxrtems_id " and 0x%" PRIxrtems_id ")\n", rmid, test_rmid ); rtems_test_exit( 0 ); } switch ( argument ) { case 1: while ( FOREVER ) { status = rtems_rate_monotonic_period( rmid, RTEMS_MILLISECONDS_TO_TICKS(8000)); directive_failed( status, "rtems_rate_monotonic_period" ); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - executing - ", &time, "\n" ); rtems_task_wake_after(RTEMS_MILLISECONDS_TO_TICKS(2000)); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - finished - ", &time, "\n" ); if ( time.second >= 30 && time.minute == 0) { printf( "PERIODS CHECK OK 30s\n"); TEST_END(); rtems_test_exit( 0 ); } } case 2: while ( FOREVER ) { status = rtems_rate_monotonic_period( rmid, RTEMS_MILLISECONDS_TO_TICKS(6000)); directive_failed( status, "rtems_rate_monotonic_period" ); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - executing - ", &time, "\n" ); rtems_task_wake_after(RTEMS_MILLISECONDS_TO_TICKS(3000)); directive_failed( status, "rtems_task_wake_after" ); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - finished - ", &time, "\n" ); } break; case 3: while ( FOREVER ) { status = rtems_rate_monotonic_period( rmid, RTEMS_MILLISECONDS_TO_TICKS(4000)); directive_failed( status, "rtems_rate_monotonic_period" ); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - executing - ", &time, "\n" ); rtems_task_wake_after(RTEMS_MILLISECONDS_TO_TICKS(1000)); directive_failed( status, "rtems_task_wake_after" ); status = rtems_clock_get_tod( &time ); directive_failed( status, "rtems_clock_get_tod" ); put_name( Task_name[ argument ], FALSE ); print_time( " - finished - ", &time, "\n" ); } break; } }
上面的代码,我在每个任务中,按照要求定义了三个任务如下
- A任务运行时间为2s,A任务的截止时间(周期)是8s
- B任务运行时间为3s,B任务的截止时间(周期)是6s
- C任务运行时间为1s,C任务的截止时间(周期)是4S
对于任务的周期创建,这里通过标准接口rtems_rate_monotonic_create和rtems_rate_monotonic_period来设置。其中RTEMS_MILLISECONDS_TO_TICKS会将ms转换成系统的tick值
对于任务的运行时间,这里通过rtems_task_wake_after来实现,它会默认将进程让出就绪队列,然后休眠超时后,将任务加入就绪队列。
当系统任务运行结束时间超过30s时,会主动退出此测试程序
接下来我们编译运行,查看运行结果
输出结果
将上述代码运行之后,可以得到如下日志
TA3 - executing - 09:00:00 04/16/2025 TA3 - finished - 09:00:01 04/16/2025 TA2 - executing - 09:00:02 04/16/2025 TA1 - executing - 09:00:04 04/16/2025 TA3 - executing - 09:00:04 04/16/2025 TA2 - finished - 09:00:05 04/16/2025 TA3 - finished - 09:00:05 04/16/2025 TA1 - finished - 09:00:06 04/16/2025 TA2 - executing - 09:00:08 04/16/2025 TA3 - executing - 09:00:08 04/16/2025 TA3 - finished - 09:00:09 04/16/2025 TA2 - finished - 09:00:11 04/16/2025 TA1 - executing - 09:00:12 04/16/2025 TA3 - executing - 09:00:12 04/16/2025 TA3 - finished - 09:00:13 04/16/2025 TA2 - executing - 09:00:14 04/16/2025 TA1 - finished - 09:00:14 04/16/2025 TA3 - executing - 09:00:16 04/16/2025 TA2 - finished - 09:00:17 04/16/2025 TA3 - finished - 09:00:17 04/16/2025 TA1 - executing - 09:00:20 04/16/2025 TA2 - executing - 09:00:20 04/16/2025 TA3 - executing - 09:00:20 04/16/2025 TA3 - finished - 09:00:21 04/16/2025 TA1 - finished - 09:00:22 04/16/2025 TA2 - finished - 09:00:23 04/16/2025 TA3 - executing - 09:00:24 04/16/2025 TA3 - finished - 09:00:25 04/16/2025 TA2 - executing - 09:00:26 04/16/2025 TA1 - executing - 09:00:28 04/16/2025 TA3 - executing - 09:00:28 04/16/2025 TA2 - finished - 09:00:29 04/16/2025 TA3 - finished - 09:00:29 04/16/2025 TA1 - finished - 09:00:30 04/16/2025 PERIODS CHECK OK 30s
分析结果
其实根据日志的输出,已经很明显看出edf调度器的工作机制了,这里逐步分析一下,方便加深edf调度算法的理解
我逐步分析如下
- 任务3优先级最高,在1s时直接执行完成,然后执行任务2,预计第5s完成
- 在第4s时,任务1作为优先级最低开始执行,预计在第6s时结束
- 因为任务3的周期是4s,所以从第4s开始,任务3也开始执行,预计第5s完成
- 我们知道任务2的周期是6s,任务3的周期是4s,第8s是第二个周期。而第6s之后,所有任务都完成了。
- 从第8s开始,任务2和任务3都得到执行,第12s时任务1得以执行
- 以此类推
根据上面的分析,我们可以发现
- 任务3优先级最高,任务2次之,任务1最低。由截止时间决定
- 在一个周期内,任务一定会运行一次
根据上面的推论,我们还可以发现
- 任务1优先级最低,所以等到任务2和任务3完成之后才能得以运行,也就是一个周期的第3+1s时
- 同理,任务2优先级次之,它需要等到任务1完成之后得以执行
- 同理,任务1优先级最高,所以每次周期开始,它都直接运行
根据上面的日志,我们可能发现,任务2每次在周期内都是在第2秒才运行,也就是2/8/20/26。而任务1时间只有1s中,那么我们可以推论,此时操作系统中,还有一个任务周期为1s的任务。它的优先级在任务3和任务2之间。不过此任务不影响我们对edf任务调度的观测和推论。
最后,我们关心任务的执行此时,如下
# cat task.log | grep TA1 | wc -l 8 # cat task.log | grep TA2 | wc -l 10 # cat task.log | grep TA3 | wc -l 16
我们以30s作为任务结束为计数,可以得到如下
- TA1 = 8/2 times * 8s = 32s
- TA2 = 10/2 times * 6s = 30s
- TA3 = 16/2 times * 4s = 32s
可以发现,完全符合edf的调度情况
总结
根据上面的演示,我们清晰的了解了edf调度的运行机制。
本文基于linux发行版安装tensorflow2程序,用作后期的调研评估,如下是步骤
安装软件
安装步骤如下
pip install -i https://mirrors.aliyun.com/pypi/simple --upgrade pip pip install -i https://mirrors.aliyun.com/pypi/simple tensorflow==2.2.0 pip install -i https://mirrors.aliyun.com/pypi/simple jupyterlab pip install -i https://mirrors.aliyun.com/pypi/simple numpy==1.20.0 pip install -i https://mirrors.aliyun.com/pypi/simple protobuf==3.20.1
值得注意的是,这里protobuf和numpy都是降级了的
jupyter的配置
为了开发tensorflow2,我们需要使用jupyter开放一个端口,默认8888,如下
{ "NotebookApp" : { "ip": "*", "port": 8888, "password": "", "open_browser": false, "token": "", "allow_root": true } }
运行jupyter
为了运行jupyter,可以新建一个shell脚本,名字为run_jupyter.sh,内容如下
jupyter lab --config jupyter_config.json
打开端口
上述动作完成之后,打开端口可以看到如下
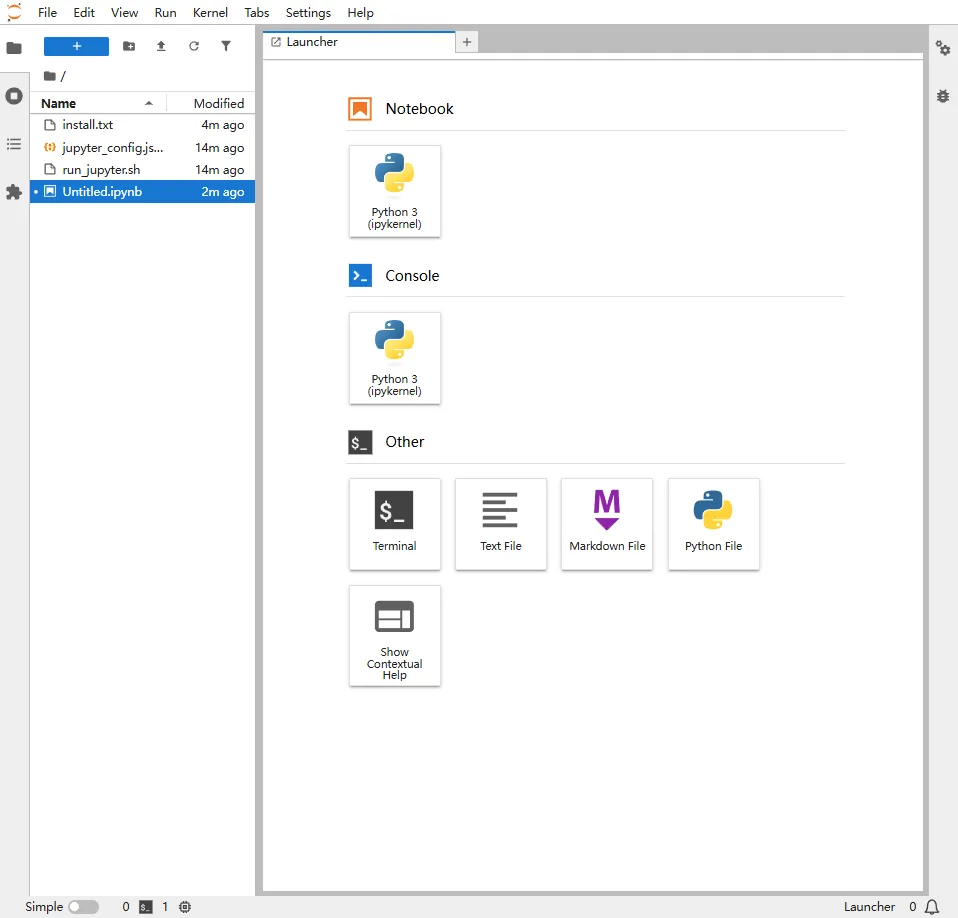
此时我们点击Notebook下的python3进行测试
测试
这里直接打印tensorflow2的版本即可,如下
至此,tensorflow的安装完成了,接下来继续调研tensorflow2
我们之前介绍了优先级调度算法和简单优先级调度算法,这两种调度算法都是基于优先级的值来调度的,也就是每个任务在创建的时候,会分配一个优先级,那么较高优先级始终比较低优先级优先调度。今天我们介绍rtems中另一种调度算法,EDF,最早截止事件调度算法
介绍EDF调度算法
对于最早截止时间调度算法而言,默认情况下会给任务分配一个截止事件,调度器根据每个任务的截止时间来确定优先级,它需要预设一个周期,当任务的实际运行时间越靠近周期设置时间,那么任务的优先级越高。这里优先级的动态调整通过的是timer来实现。
下面通过图示来介绍一下EDF调度算法的工作规则
现在加上,有任务A,B,C共三个任务,其中:
- A任务运行时间为2s,A任务的截止时间(周期)是8s
- B任务运行时间为3s,B任务的截止时间(周期)是6s
- C任务运行时间为1s,C任务的截止时间(周期)是4S
根据上面的信息,实际EDF的执行流程会如下表现
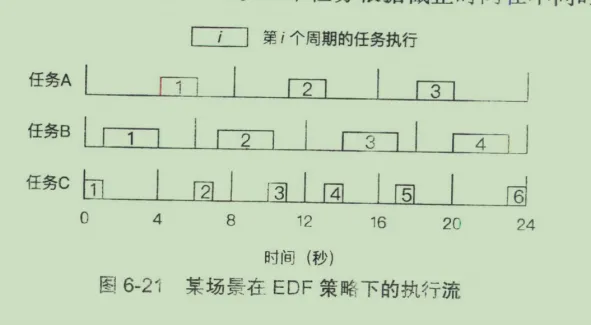
光看图片可能不好理解,如下解释一下就清楚了:
- 根据EDF调度的定义,从0时刻开始调度,那么C的优先级最高,因为C的截止时间最短
- 到第1s的时候,C任务完成执行,但是还没有到周期,此时B任务截止时间是5,A任务截止时间是7,此时B优先级高
- 到第4s的时候,B任务完成调度,此时C任务也到达周期,C任务的截止时间是4,A任务的截止时间是4,但是A先如的队列,默认执行A
- 到第6s的时候,A任务完成执行,此时B任务到达周期,B任务截止时间是6,C任务优先级最高,默认执行C
- 到第7s的时候,C任务完成,开始执行B任务
- 到第10s的时候,B任务完成,并且没到截止时间,此时A任务的截止时间是8s,C任务优先执行
- 第11s的时候,A任务得以执行,因为B和C都未到截止时间
- 以此类推。
根据上面的详细解释,我们知道了edf调度算法的执行逻辑,下面查看实现
预设周期
根据上面分析的,如果我们需要使用edf调度算法将任务运行,那么任务必须要有一个周期值设置,在rtems中,设置周期的方式如下
status = rtems_rate_monotonic_create( argument, &rmid ); status = rtems_rate_monotonic_period( rmid, Periods[ argument ] ); status = rtems_rate_monotonic_delete( rmid );
上面的意思非常容易理解,就是为edf调度器设置一个周期,其实现通过timer。
那其实际对timer的操作如下
_Watchdog_Initialize( &the_period->Timer, _Rate_monotonic_Timeout ); deadline = _Watchdog_Per_CPU_insert_ticks( &the_period->Timer, cpu_self, next_length );
值得注意的是,这里会提前设置周期的长度为 Periods的值,如下
the_period->next_length = length;
所以当timeout的时候,会再次重启timer。
_Rate_monotonic_Restart( the_period, owner, &lock_context );
或
_Rate_monotonic_Renew_deadline( the_period, &lock_context );
根据截止时间设置优先级
根据上面的介绍,我们知道了edf调度算法会通过截止时间来动态调整优先级,也知道了默认情况下我们会预先设置一个周期值,这个周期值就是rtems_rate_monotonic_period的第二个参数,接下来,我们需要明确edf算法如何根据截止时间来动态调整优先级
首先,我们关注_Rate_monotonic_Release_job函数,其实现如下
static void _Rate_monotonic_Release_job( Rate_monotonic_Control *the_period, Thread_Control *owner, rtems_interval next_length, ISR_lock_Context *lock_context ) { Per_CPU_Control *cpu_self; Thread_queue_Context queue_context; uint64_t deadline; cpu_self = _Thread_Dispatch_disable_critical( lock_context ); deadline = _Watchdog_Per_CPU_insert_ticks( &the_period->Timer, cpu_self, next_length ); _Scheduler_Release_job( owner, &the_period->Priority, deadline, &queue_context ); _Rate_monotonic_Release( the_period, lock_context ); _Thread_Priority_update( &queue_context ); _Thread_Dispatch_enable( cpu_self ); }
上述函数的步骤如下
- 为周期值开启一个定时器watchdog,返回定时器的时间period
- 根据定时器时间来确定deadline
- 根据deadline来调整scheduler edf的优先级Priority
- 在edf调度器中更新优先级的值
- 打开线程dispatch
我将关键点函数提取出来如下
rtems_rate_monotonic_period( rmid, Periods[ argument ] ); _Watchdog_Insert(header, the_watchdog, expire); deadline = _Watchdog_Per_CPU_insert_ticks(*) _Priority_Node_set_priority(*) _Thread_Priority_update( &queue_context ); _Thread_Dispatch_enable( cpu_self );
根据上面的代码流程,我们知道了,在edf调度算法中,一个周期Period内,优先级是根据watchdog的expire来动态调整,expire的值会换算成调度器的priority值,edf调度算法根据此值来动态调整任务的优先级
红黑树管理优先级
对于调度器的优先级管理,edf中使用的是红黑树,其主要函数如下
_Scheduler_EDF_Schedule, /* schedule entry point */ \ _Scheduler_EDF_Yield, /* yield entry point */ \ _Scheduler_EDF_Block, /* block entry point */ \ _Scheduler_EDF_Unblock, /* unblock entry point */ \ _Scheduler_EDF_Update_priority, /* update priority entry point */ \
下面我们逐个介绍调度器管理优先级的方式
执行调度
_Scheduler_EDF_Schedule的作用是将当前任务调度一次,此时需要获得优先级最高的任务,对于edf而言,默认expire值最小说明优先级越高,所以在红黑树中是获得最小的节点,在红黑树获得最小节点的方式是遍历根节点,找其左孩子
那么执行调度过程中,获得最高优先级任务的方式如下
RBTree_Node *_RBTree_Minimum( const RBTree_Control *tree ) { RBTree_Node *parent; RBTree_Node *node; parent = NULL; node = _RBTree_Root( tree ); while ( node != NULL ) { parent = node; node = _RBTree_Left( node ); } return parent; }
当找到优先级最高的任务之后,直接设置其标志位为true即可
_Scheduler_uniprocessor_Schedule _Thread_Dispatch_necessary = true;
让出任务
对于让出任务而言,我们需要做的是
- 将任务从红黑树中删除
- 根据新的优先级,将任务插入到红黑树中
- 执行调度
关于1,其实就是红黑树的删除操作,其代码如下
RTEMS_RB_REMOVE( RBTree_Control, the_rbtree, the_node );
关于红黑树的删除,可以查看文章<rb-tree实现-删除操作-原理>
关于2,其实就是红黑树的插入操作,其代码如下
static inline bool _RBTree_Insert_inline( RBTree_Control *the_rbtree, RBTree_Node *the_node, const void *key, bool ( *less )( const void *, const RBTree_Node * ) ) { RBTree_Node **link; RBTree_Node *parent; bool is_new_minimum; link = _RBTree_Root_reference( the_rbtree ); parent = NULL; is_new_minimum = true; while ( *link != NULL ) { parent = *link; if ( ( *less )( key, parent ) ) { link = _RBTree_Left_reference( parent ); } else { link = _RBTree_Right_reference( parent ); is_new_minimum = false; } } _RBTree_Add_child( the_node, parent, link ); _RBTree_Insert_color( the_rbtree, the_node ); return is_new_minimum; }
根据上面的代码,我们可以知道,在插入之前,我们需要遍历根节点,找到小于等于某个节点的位置,然后如果待插入节点插入到其节点的左边。然后执行红黑树的插入操作_RBTree_Insert_color
关于红黑树的插入,可以查看文章<rb-tree实现-插入操作-原理>
阻塞任务
对于阻塞当前任务,我们需要做的是
- 将任务从红黑树中删除
- 执行调度
代码如下
static inline void _Scheduler_uniprocessor_Block( const Scheduler_Control *scheduler, Thread_Control *the_thread, Scheduler_Node *node, void ( *extract )( const Scheduler_Control *, Thread_Control *, Scheduler_Node * ), Thread_Control *( *get_highest_ready )( const Scheduler_Control * ) ) { ( *extract )( scheduler, the_thread, node ); /* TODO: flash critical section? */ if ( _Thread_Is_heir( the_thread ) ) { Thread_Control *highest_ready; highest_ready = ( *get_highest_ready )( scheduler ); _Scheduler_uniprocessor_Update_heir( _Thread_Heir, highest_ready ); } }
恢复任务
对于当前任务恢复调度,就是将其加入就绪队列中,也就是红黑树的插入操作,其代码如下
void _Scheduler_EDF_Unblock( const Scheduler_Control *scheduler, Thread_Control *the_thread, Scheduler_Node *node ) { Scheduler_EDF_Context *context; Scheduler_EDF_Node *the_node; Priority_Control priority; Priority_Control insert_priority; context = _Scheduler_EDF_Get_context( scheduler ); the_node = _Scheduler_EDF_Node_downcast( node ); priority = _Scheduler_Node_get_priority( &the_node->Base ); priority = SCHEDULER_PRIORITY_PURIFY( priority ); insert_priority = SCHEDULER_PRIORITY_APPEND( priority ); the_node->priority = priority; _Scheduler_EDF_Enqueue( context, the_node, insert_priority ); _Scheduler_uniprocessor_Unblock( scheduler, the_thread, priority ); }
这里就绪队列的入队_Scheduler_EDF_Enqueue就是红黑树的插入操作
总结
至此,我们讲解了edf调度的原理,接下来通过实验来演示edf调度
